 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Retrieval and Localization in Large Art Collections using Deep Multi-Style Feature Fusion and Iterative Voting
Jul 14, 2021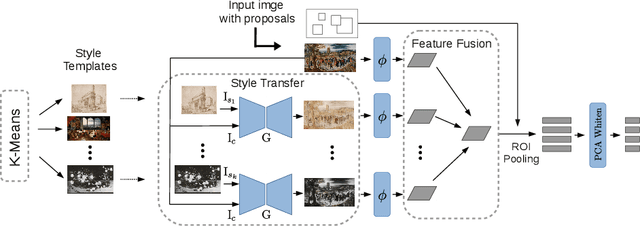

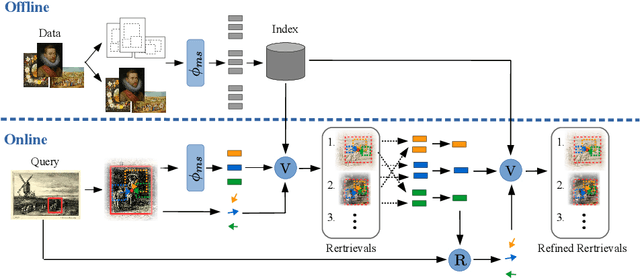

The search for specific objects or motifs is essential to art history as both assist in decoding the meaning of artworks. Digitization has produced large art collections, but manual methods prove to be insufficient to analyze them. In the following, we introduce an algorithm that allows users to search for image regions containing specific motifs or objects and find similar regions in an extensive dataset, helping art historians to analyze large digitized art collections. Computer vision has presented efficient methods for visual instance retrieval across photographs. However, applied to art collections, they reveal severe deficiencies because of diverse motifs and massive domain shifts induced by differences in techniques, materials, and styles. In this paper, we present a multi-style feature fusion approach that successfully reduces the domain gap and improves retrieval results without labelled data or curated image collections. Our region-based voting with GPU-accelerated approximate nearest-neighbour search allows us to find and localize even small motifs within an extensive dataset in a few seconds. We obtain state-of-the-art results on the Brueghel dataset and demonstrate its generalization to inhomogeneous collections with a large number of distractors.
Multi-Scale Convolutions for Learning Context Aware Feature Representations
Jun 17, 2019
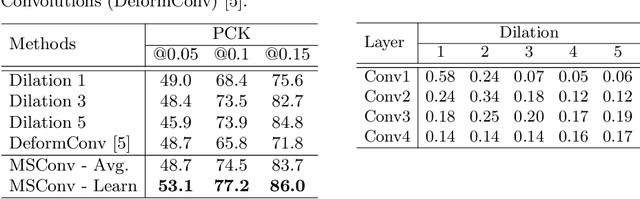

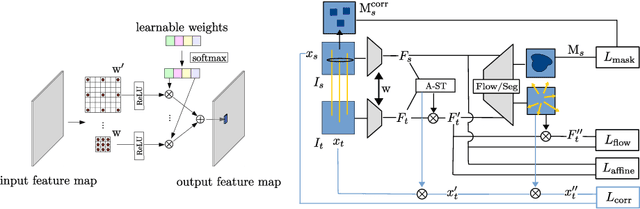
Finding semantic correspondences is a challenging problem. With the breakthrough of CNNs stronger features are available for tasks like classification but not specifically for the requirements of semantic matching. In the following we present a weakly supervised metric learning approach which generates stronger features by encoding far more context than previous methods. First, we generate more suitable training data using a geometrically informed correspondence mining method which is less prone to spurious matches and requires only image category labels as supervision. Second, we introduce a new convolutional layer which is a learned mixture of differently strided convolutions and allows the network to encode implicitly more context while preserving matching accuracy at the same time. The strong geometric encoding on the feature side enables us to learn a semantic flow network, which generates more natural deformations than parametric transformation based models and is able to jointly predict foreground regions at the same time. Our semantic flow network outperforms current state-of-the-art on several semantic matching benchmarks and the learned features show astonishing performance regarding simple nearest neighbor matching.