 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Span Measure, Spanning Sets and Applications
Jul 22, 2021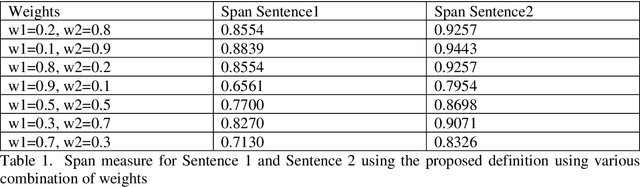
Rough Set based Spanning Sets were recently proposed to deal with uncertainties arising in the problem in domain of natural language processing problems. This paper presents a novel span measure using upper approximations. The key contribution of this paper is to propose another uncertainty measure of span and spanning sets. Firstly, this paper proposes a new definition of computing span which use upper approximation instead of boundary regions. This is useful in situations where computing upper approximations are much more convenient that computing boundary region. Secondly, properties of novel span and relation with earlier span measure are discussed. Thirdly, the paper presents application areas where the proposed span measure can be utilized.
Decision Making Using Rough Set based Spanning Sets for a Decision System
Jul 21, 2021
Rough Set based concepts of Span and Spanning Sets were recently proposed to deal with uncertainties in data. Here, this paper, presents novel concepts for generic decision-making process using Rough Set based span for a decision table. Majority of problems in Artificial Intelligence deal with decision making. This paper provides real life applications of proposed Rough Set based span for decision tables. Here, novel concept of span for a decision table is proposed, illustrated with real life example of flood relief and rescue team assignment. Its uses, applications and properties are explored. The key contribution of paper is primarily to study decision making using Rough Set based Span for a decision tables, as against an information system in prior works. Here, the main contribution is that decision classes are automatically learned by the technique of Rough Set based span, for a particular problem, hence automating the decision-making process. These decision-making tools based on span can guide an expert in taking decisions in tough and time-bound situations.
Computing Fuzzy Rough Set based Similarities with Fuzzy Inference and Its Application to Sentence Similarity Computations
Jul 02, 2021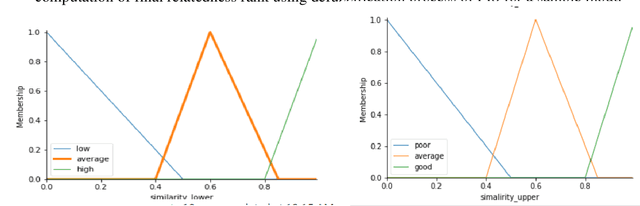
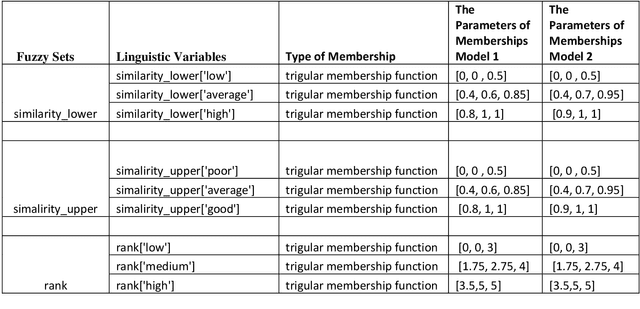

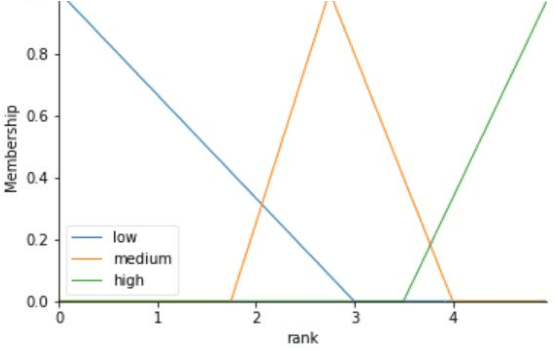
Several research initiatives have been proposed for computing similarity between two Fuzzy Sets in analysis through Fuzzy Rough Sets. These techniques yield two measures viz. lower similarity and upper similarity. While in most applications only one entity is useful to further analysis and for drawing conclusions. The aim of this paper is to propose novel technique to combine Fuzzy Rough Set based lower similarity and upper similarity using Fuzzy Inference Engine. Further, the proposed approach is applied to the problem computing sentence similarity and have been evaluated on SICK2014 dataset.
Neighborhood Rough Set based Multi-document Summarization
May 27, 2021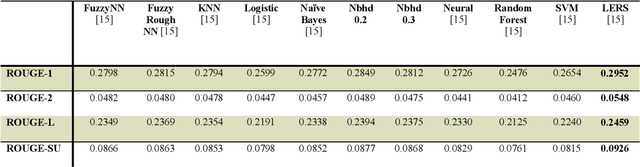
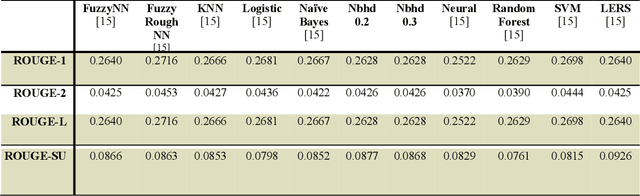
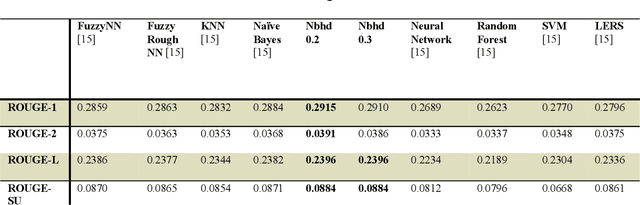
This research paper proposes a novel Neighbourhood Rough Set based approach for supervised Multi-document Text Summarization (MDTS) with analysis and impact on the summarization results for MDTS. Here, Rough Set based LERS algorithm is improved using Neighborhood Rough Set which is itself a novel combination called Neighborhood-LERS to be experimented for evaluations of efficacy and efficiency. In this paper, we shall apply and evaluate the proposed Neighborhood-LERS for Multi-document Summarization which here is proved experimentally to be superior to the base LERS technique for MDTS.
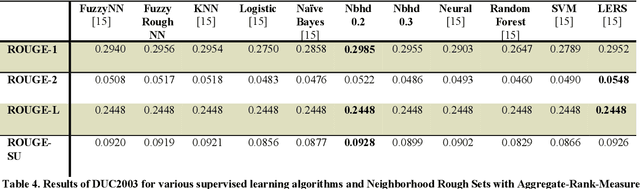
Rough Set based Aggregate Rank Measure & its Application to Supervised Multi Document Summarization
Feb 09, 2020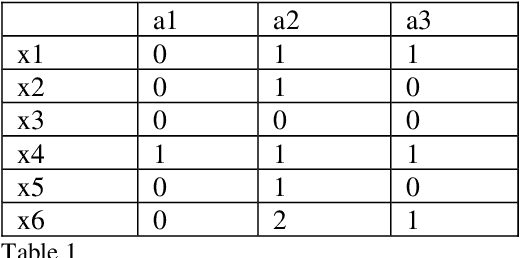

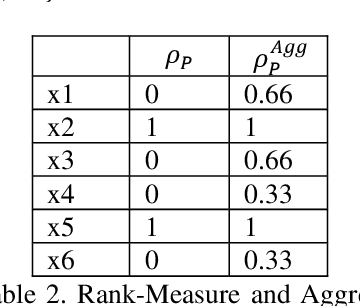

Most problems in Machine Learning cater to classification and the objects of universe are classified to a relevant class. Ranking of classified objects of universe per decision class is a challenging problem. We in this paper propose a novel Rough Set based membership called Rank Measure to solve to this problem. It shall be utilized for ranking the elements to a particular class. It differs from Pawlak Rough Set based membership function which gives an equivalent characterization of the Rough Set based approximations. It becomes paramount to look beyond the traditional approach of computing memberships while handling inconsistent, erroneous and missing data that is typically present in real world problems. This led us to propose the aggregate Rank Measure. The contribution of the paper is three fold. Firstly, it proposes a Rough Set based measure to be utilized for numerical characterization of within class ranking of objects. Secondly, it proposes and establish the properties of Rank Measure and aggregate Rank Measure based membership. Thirdly, we apply the concept of membership and aggregate ranking to the problem of supervised Multi Document Summarization wherein first the important class of sentences are determined using various supervised learning techniques and are post processed using the proposed ranking measure. The results proved to have significant improvement in accuracy.