 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing the speed-accuracy simulation trade-off for adaptive spiking neurons
Nov 19, 2023

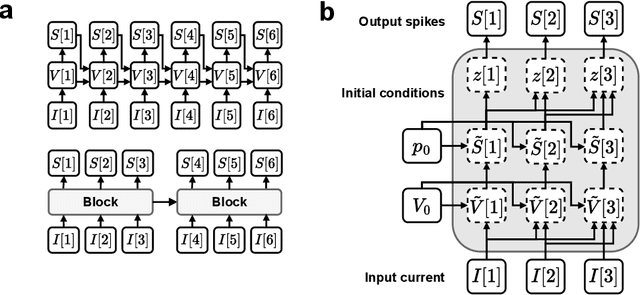

The adaptive leaky integrate-and-fire (ALIF) model is fundamental within computational neuroscience and has been instrumental in studying our brains $\textit{in silico}$. Due to the sequential nature of simulating these neural models, a commonly faced issue is the speed-accuracy trade-off: either accurately simulate a neuron using a small discretisation time-step (DT), which is slow, or more quickly simulate a neuron using a larger DT and incur a loss in simulation accuracy. Here we provide a solution to this dilemma, by algorithmically reinterpreting the ALIF model, reducing the sequential simulation complexity and permitting a more efficient parallelisation on GPUs. We computationally validate our implementation to obtain over a $50\times$ training speedup using small DTs on synthetic benchmarks. We also obtained a comparable performance to the standard ALIF implementation on different supervised classification tasks - yet in a fraction of the training time. Lastly, we showcase how our model makes it possible to quickly and accurately fit real electrophysiological recordings of cortical neurons, where very fine sub-millisecond DTs are crucial for capturing exact spike timing.
* 15 pages, 5 figures