 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Recognition in the Wild
May 05, 2022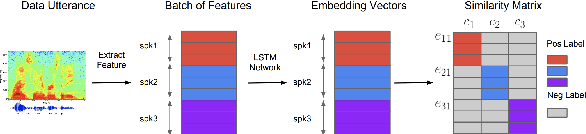

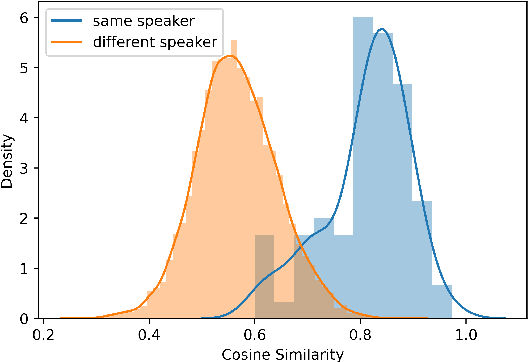
In this paper, we propose a pipeline to find the number of speakers, as well as audios belonging to each of these now identified speakers in a source of audio data where number of speakers or speaker labels are not known a priori. We used this approach as a part of our Data Preparation pipeline for Speech Recognition in Indic Languages (https://github.com/Open-Speech-EkStep/vakyansh-wav2vec2-experimentation). To understand and evaluate the accuracy of our proposed pipeline, we introduce two metrics: Cluster Purity, and Cluster Uniqueness. Cluster Purity quantifies how "pure" a cluster is. Cluster Uniqueness, on the other hand, quantifies what percentage of clusters belong only to a single dominant speaker. We discuss more on these metrics in section \ref{sec:metrics}. Since we develop this utility to aid us in identifying data based on speaker IDs before training an Automatic Speech Recognition (ASR) model, and since most of this data takes considerable effort to scrape, we also conclude that 98\% of data gets mapped to the top 80\% of clusters (computed by removing any clusters with less than a fixed number of utterances -- we do this to get rid of some very small clusters and use this threshold as 30), in the test set chosen.
indic-punct: An automatic punctuation restoration and inverse text normalization framework for Indic languages
Mar 31, 2022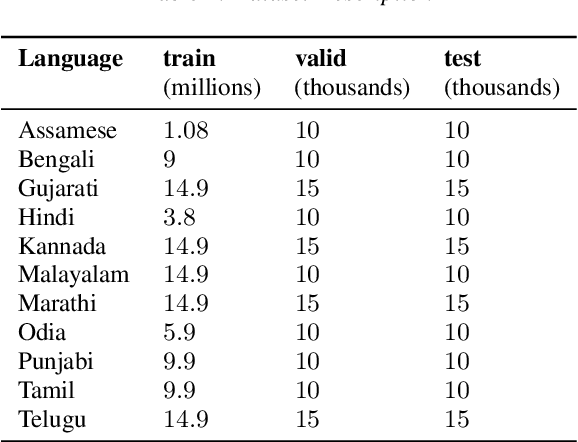
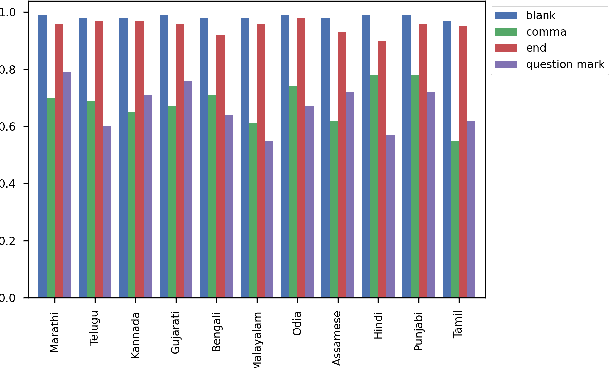
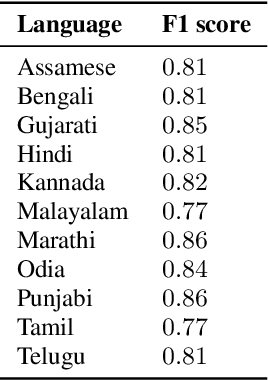
Automatic Speech Recognition (ASR) generates text which is most of the times devoid of any punctuation. Absence of punctuation is text can affect readability. Also, down stream NLP tasks such as sentiment analysis, machine translation, greatly benefit by having punctuation and sentence boundary information. We present an approach for automatic punctuation of text using a pretrained IndicBERT model. Inverse text normalization is done by hand writing weighted finite state transducer (WFST) grammars. We have developed this tool for 11 Indic languages namely Hindi, Tamil, Telugu, Kannada, Gujarati, Marathi, Odia, Bengali, Assamese, Malayalam and Punjabi. All code and data is publicly. available
Effectiveness of text to speech pseudo labels for forced alignment and cross lingual pretrained models for low resource speech recognition
Mar 31, 2022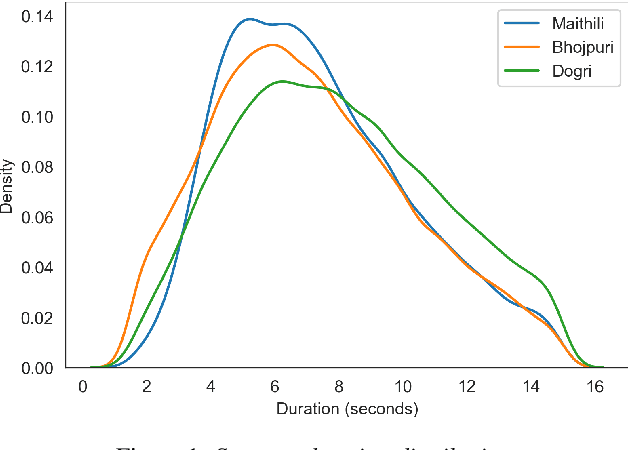
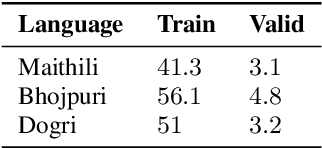
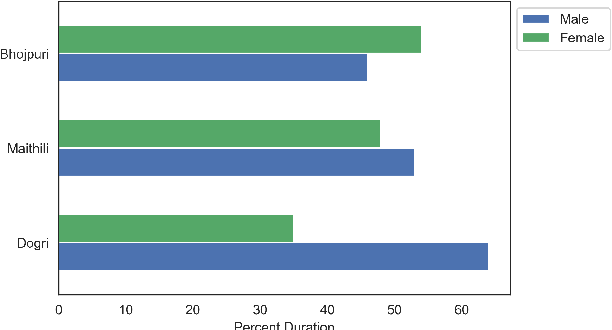
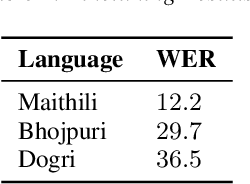
In the recent years end to end (E2E) automatic speech recognition (ASR) systems have achieved promising results given sufficient resources. Even for languages where not a lot of labelled data is available, state of the art E2E ASR systems can be developed by pretraining on huge amounts of high resource languages and finetune on low resource languages. For a lot of low resource languages the current approaches are still challenging, since in many cases labelled data is not available in open domain. In this paper we present an approach to create labelled data for Maithili, Bhojpuri and Dogri by utilising pseudo labels from text to speech for forced alignment. The created data was inspected for quality and then further used to train a transformer based wav2vec 2.0 ASR model. All data and models are available in open domain.
Is Word Error Rate a good evaluation metric for Speech Recognition in Indic Languages?
Mar 30, 2022
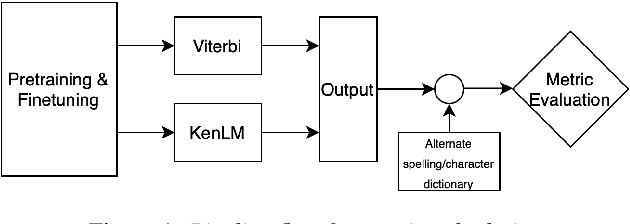

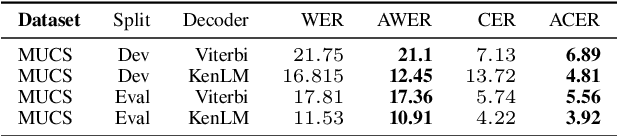
We propose a new method for the calculation of error rates in Automatic Speech Recognition (ASR). This new metric is for languages that contain half characters and where the same character can be written in different forms. We implement our methodology in Hindi which is one of the main languages from Indic context and we think this approach is scalable to other similar languages containing a large character set. We call our metrics Alternate Word Error Rate (AWER) and Alternate Character Error Rate (ACER). We train our ASR models using wav2vec 2.0\cite{baevski2020wav2vec} for Indic languages. Additionally we use language models to improve our model performance. Our results show a significant improvement in analyzing the error rates at word and character level and the interpretability of the ASR system is improved upto $3$\% in AWER and $7$\% in ACER for Hindi. Our experiments suggest that in languages which have complex pronunciation, there are multiple ways of writing words without changing their meaning. In such cases AWER and ACER will be more useful rather than WER and CER as metrics. Furthermore, we open source a new benchmarking dataset of 21 hours for Hindi with the new metric scripts.
Improving Speech Recognition for Indic Languages using Language Model
Mar 30, 2022
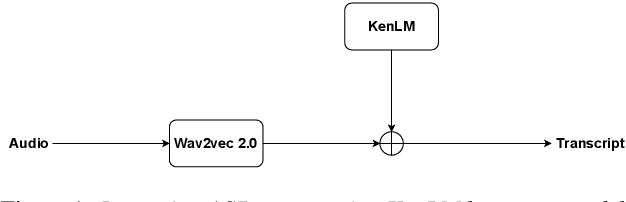
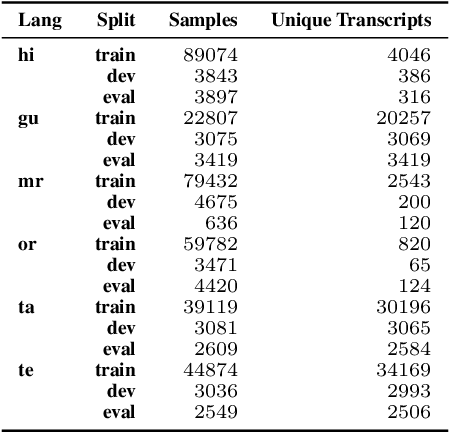
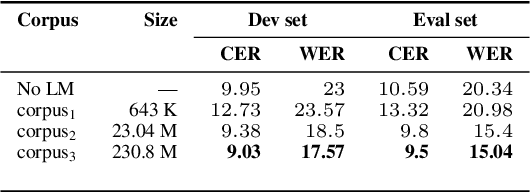
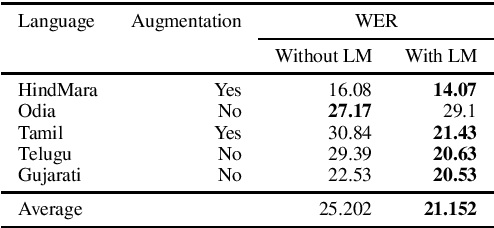
We study the effect of applying a language model (LM) on the output of Automatic Speech Recognition (ASR) systems for Indic languages. We fine-tune wav2vec $2.0$ models for $18$ Indic languages and adjust the results with language models trained on text derived from a variety of sources. Our findings demonstrate that the average Character Error Rate (CER) decreases by over $28$ \% and the average Word Error Rate (WER) decreases by about $36$ \% after decoding with LM. We show that a large LM may not provide a substantial improvement as compared to a diverse one. We also demonstrate that high quality transcriptions can be obtained on domain-specific data without retraining the ASR model and show results on biomedical domain.
Code Switched and Code Mixed Speech Recognition for Indic languages
Mar 30, 2022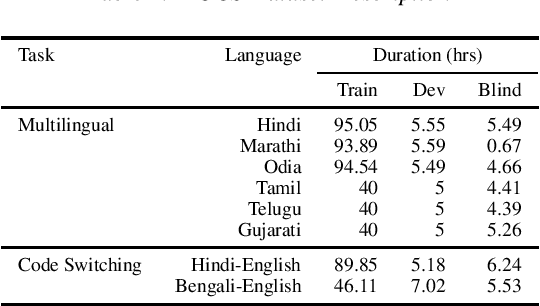

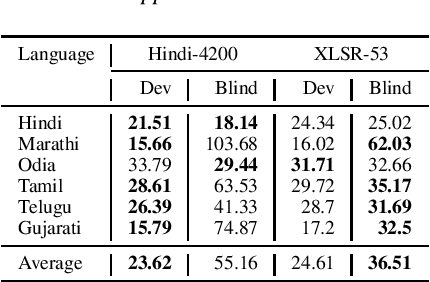
Training multilingual automatic speech recognition (ASR) systems is challenging because acoustic and lexical information is typically language specific. Training multilingual system for Indic languages is even more tougher due to lack of open source datasets and results on different approaches. We compare the performance of end to end multilingual speech recognition system to the performance of monolingual models conditioned on language identification (LID). The decoding information from a multilingual model is used for language identification and then combined with monolingual models to get an improvement of 50% WER across languages. We also propose a similar technique to solve the Code Switched problem and achieve a WER of 21.77 and 28.27 over Hindi-English and Bengali-English respectively. Our work talks on how transformer based ASR especially wav2vec 2.0 can be applied in developing multilingual ASR and code switched ASR for Indic languages.
Vakyansh: ASR Toolkit for Low Resource Indic languages
Mar 30, 2022
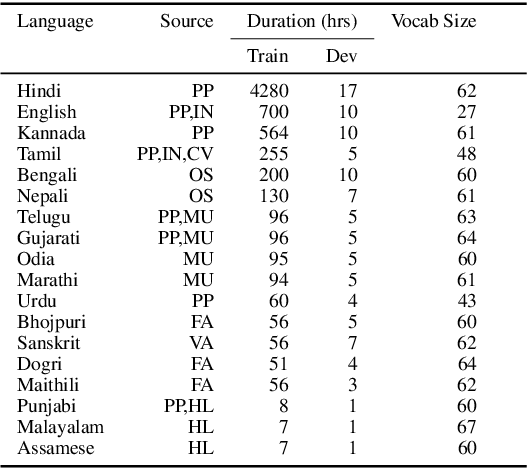

We present Vakyansh, an end to end toolkit for Speech Recognition in Indic languages. India is home to almost 121 languages and around 125 crore speakers. Yet most of the languages are low resource in terms of data and pretrained models. Through Vakyansh, we introduce automatic data pipelines for data creation, model training, model evaluation and deployment. We create 14,000 hours of speech data in 23 Indic languages and train wav2vec 2.0 based pretrained models. These pretrained models are then finetuned to create state of the art speech recognition models for 18 Indic languages which are followed by language models and punctuation restoration models. We open source all these resources with a mission that this will inspire the speech community to develop speech first applications using our ASR models in Indic languages.