 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-based Intrinsic Exploration For Sample Efficient Reinforcement Learning
Jun 28, 2022

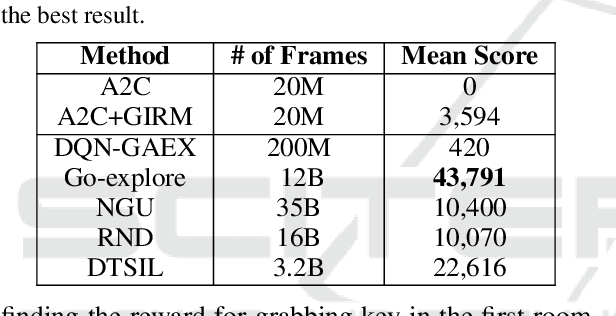

In this study, we address the problem of efficient exploration in reinforcement learning. Most common exploration approaches depend on random action selection, however these approaches do not work well in environments with sparse or no rewards. We propose Generative Adversarial Network-based Intrinsic Reward Module that learns the distribution of the observed states and sends an intrinsic reward that is computed as high for states that are out of distribution, in order to lead agent to unexplored states. We evaluate our approach in Super Mario Bros for a no reward setting and in Montezuma's Revenge for a sparse reward setting and show that our approach is indeed capable of exploring efficiently. We discuss a few weaknesses and conclude by discussing future works.