 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource allocation in dynamic multiagent systems
Feb 16, 2021

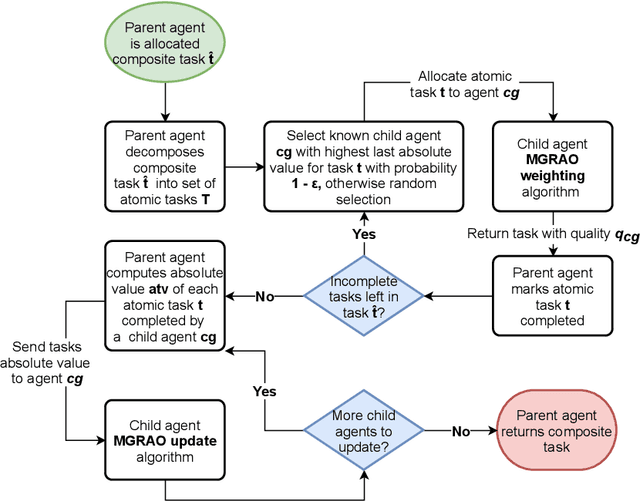

Resource allocation and task prioritisation are key problem domains in the fields of autonomous vehicles, networking, and cloud computing. The challenge in developing efficient and robust algorithms comes from the dynamic nature of these systems, with many components communicating and interacting in complex ways. The multi-group resource allocation optimisation (MG-RAO) algorithm we present uses multiple function approximations of resource demand over time, alongside reinforcement learning techniques, to develop a novel method of optimising resource allocation in these multi-agent systems. This method is applicable where there are competing demands for shared resources, or in task prioritisation problems. Evaluation is carried out in a simulated environment containing multiple competing agents. We compare the new algorithm to an approach where child agents distribute their resources uniformly across all the tasks they can be allocated. We also contrast the performance of the algorithm where resource allocation is modelled separately for groups of agents, as to being modelled jointly over all agents. The MG-RAO algorithm shows a 23 - 28% improvement over fixed resource allocation in the simulated environments. Results also show that, in a volatile system, using the MG-RAO algorithm configured so that child agents model resource allocation for all agents as a whole has 46.5% of the performance of when it is set to model multiple groups of agents. These results demonstrate the ability of the algorithm to solve resource allocation problems in multi-agent systems and to perform well in dynamic environments.
Dynamic neighbourhood optimisation for task allocation using multi-agent
Feb 16, 2021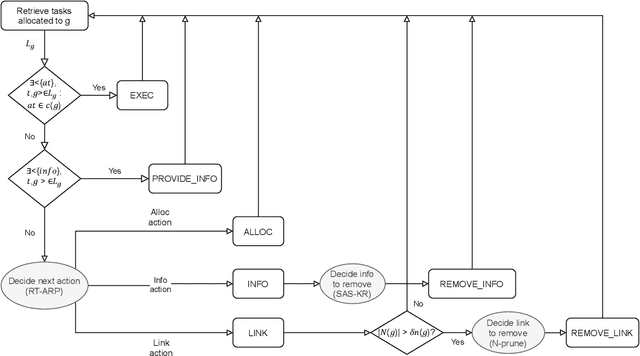
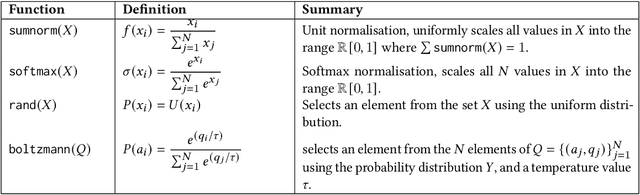
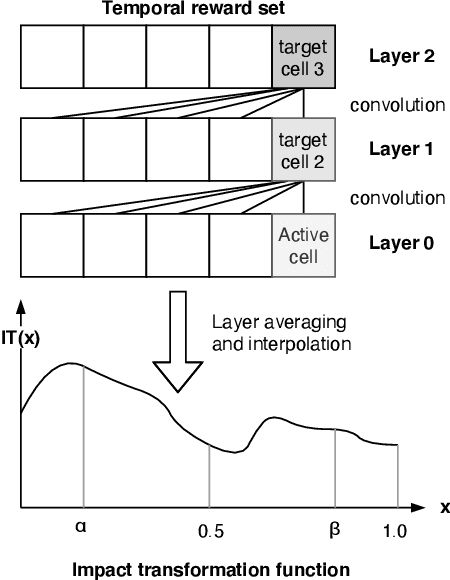

In large-scale systems there are fundamental challenges when centralised techniques are used for task allocation. The number of interactions is limited by resource constraints such as on computation, storage, and network communication. We can increase scalability by implementing the system as a distributed task-allocation system, sharing tasks across many agents. However, this also increases the resource cost of communications and synchronisation, and is difficult to scale. In this paper we present four algorithms to solve these problems. The combination of these algorithms enable each agent to improve their task allocation strategy through reinforcement learning, while changing how much they explore the system in response to how optimal they believe their current strategy is, given their past experience. We focus on distributed agent systems where the agents' behaviours are constrained by resource usage limits, limiting agents to local rather than system-wide knowledge. We evaluate these algorithms in a simulated environment where agents are given a task composed of multiple subtasks that must be allocated to other agents with differing capabilities, to then carry out those tasks. We also simulate real-life system effects such as networking instability. Our solution is shown to solve the task allocation problem to 6.7% of the theoretical optimal within the system configurations considered. It provides 5x better performance recovery over no-knowledge retention approaches when system connectivity is impacted, and is tested against systems up to 100 agents with less than a 9% impact on the algorithms' performance.