 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Evaluation of DNN for Past Dataset in Incremental Learning
May 10, 2024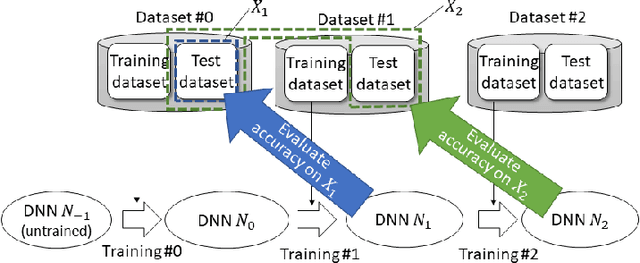
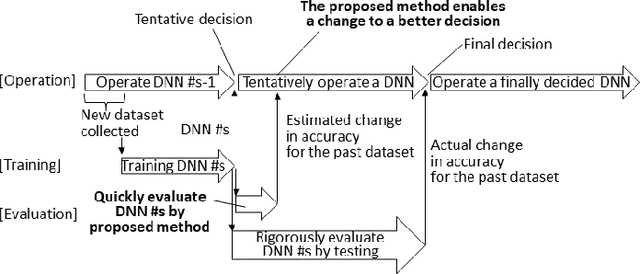
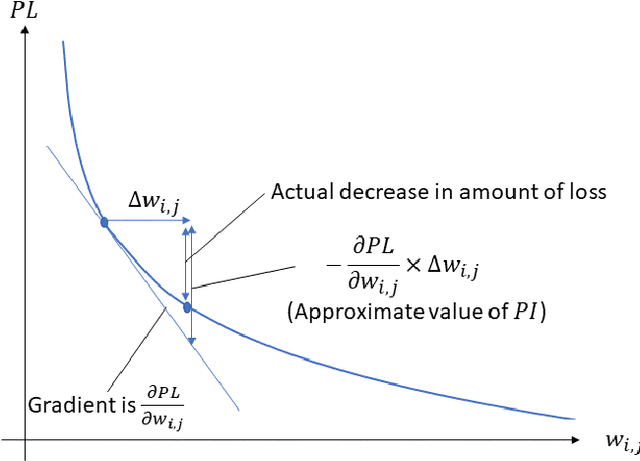
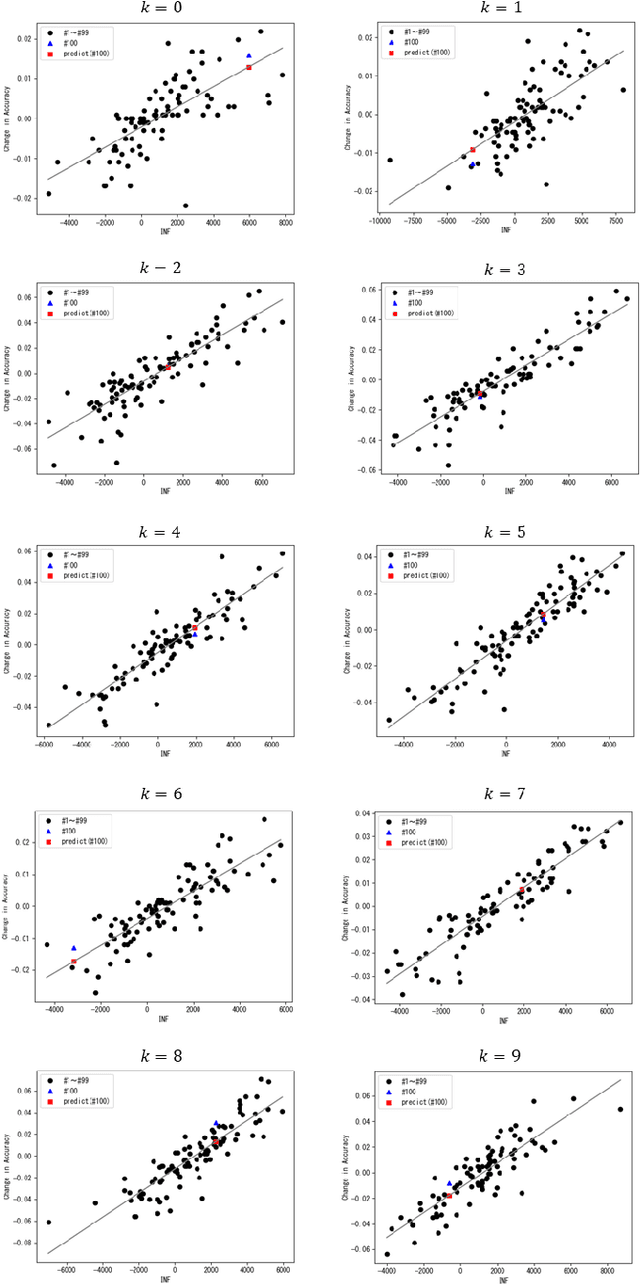
During the operation of a system including a deep neural network (DNN), new input values that were not included in the training dataset are given to the DNN. In such a case, the DNN may be incrementally trained with the new input values; however, that training may reduce the accuracy of the DNN in regard to the dataset that was previously obtained and used for the past training. It is necessary to evaluate the effect of the additional training on the accuracy for the past dataset. However, evaluation by testing all the input values included in the past dataset takes time. Therefore, we propose a new method to quickly evaluate the effect on the accuracy for the past dataset. In the proposed method, the gradient of the parameter values (such as weight and bias) for the past dataset is extracted by running the DNN before the training. Then, after the training, its effect on the accuracy with respect to the past dataset is calculated from the gradient and update differences of the parameter values. To show the usefulness of the proposed method, we present experimental results with several datasets. The results show that the proposed method can estimate the accuracy change by additional training in a constant time.
Unsupposable Test-data Generation for Machine-learned Software
May 21, 2020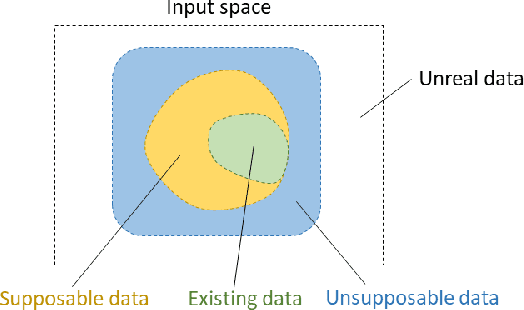


As for software development by machine learning, a trained model is evaluated by using part of an existing dataset as test data. However, if data with characteristics that differ from the existing data is input, the model does not always behave as expected. Accordingly, to confirm the behavior of the model more strictly, it is necessary to create data that differs from the existing data and test the model with that different data. The data to be tested includes not only data that developers can suppose (supposable data) but also data they cannot suppose (unsupposable data). To confirm the behavior of the model strictly, it is important to create as much unsupposable data as possible. In this study, therefore, a method called "unsupposable test-data generation" (UTG)---for giving suggestions for unsupposable data to model developers and testers---is proposed. UTG uses a variational autoencoder (VAE) to generate unsupposable data. The unsupposable data is generated by acquiring latent values with low occurrence probability in the prior distribution of the VAE and inputting the acquired latent values into the decoder. If unsupposable data is included in the data generated by the decoder, the developer can recognize new unsupposable features by referring to the data. On the basis of those unsupposable features, the developer will be able to create other unsupposable data with the same features. The proposed UTG was applied to the MNIST dataset and the House Sales Price dataset. The results demonstrate the feasibility of UTG.
Formal Verification of Decision-Tree Ensemble Model and Detection of its Violating-input-value Ranges
Apr 26, 2019



As one type of machine-learning model, a "decision-tree ensemble model" (DTEM) is represented by a set of decision trees. A DTEM is mainly known to be valid for structured data; however, like other machine-learning models, it is difficult to train so that it returns the correct output value for any input value. Accordingly, when a DTEM is used in regard to a system that requires reliability, it is important to comprehensively detect input values that lead to malfunctions of a system (failures) during development and take appropriate measures. One conceivable solution is to install an input filter that controls the input to the DTEM, and to use separate software to process input values that may lead to failures. To develop the input filter, it is necessary to specify the filtering condition of the input value that leads to the malfunction of the system. Given that necessity, in this paper, we propose a method for formally verifying a DTEM and, according to the result of the verification, if an input value leading to a failure is found, extracting the range in which such an input value exists. The proposed method can comprehensively extract the range in which the input value leading to the failure exists; therefore, by creating an input filter based on that range, it is possible to prevent the failure occurring in the system. In this paper, the algorithm of the proposed method is described, and the results of a case study using a dataset of house prices are presented. On the basis of those results, the feasibility of the proposed method is demonstrated, and its scalability is evaluated.
DeepSaucer: Unified Environment for Verifying Deep Neural Networks
Nov 09, 2018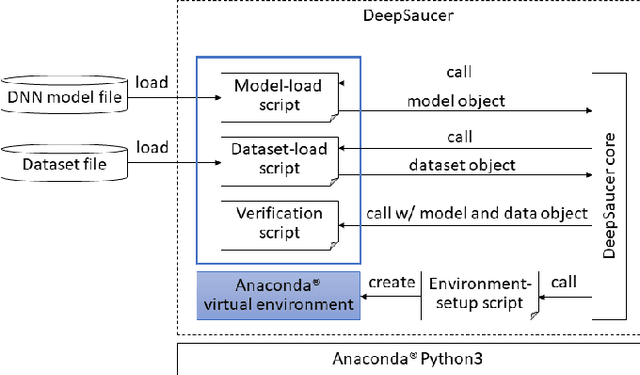
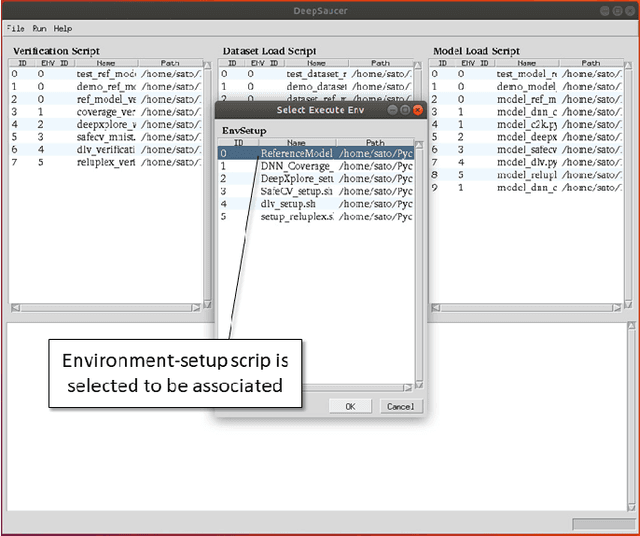
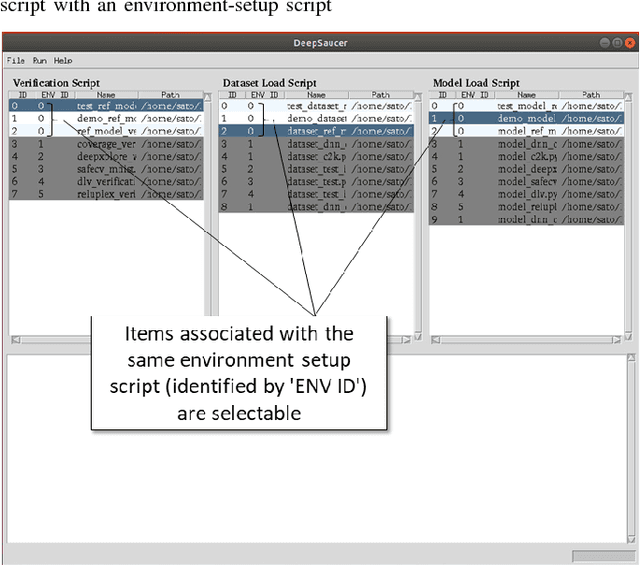
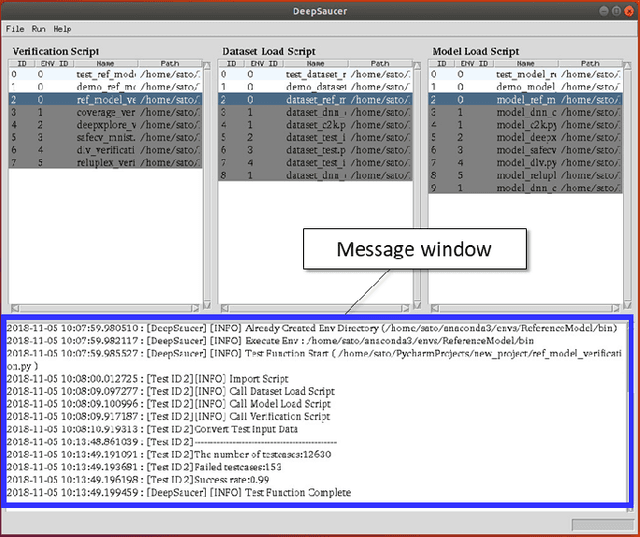
In recent years, a number of methods for verifying DNNs have been developed. Because the approaches of the methods differ and have their own limitations, we think that a number of verification methods should be applied to a developed DNN. To apply a number of methods to the DNN, it is necessary to translate either the implementation of the DNN or the verification method so that one runs in the same environment as the other. Since those translations are time-consuming, a utility tool, named DeepSaucer, which helps to retain and reuse implementations of DNNs, verification methods, and their environments, is proposed. In DeepSaucer, code snippets of loading DNNs, running verification methods, and creating their environments are retained and reused as software assets in order to reduce cost of verifying DNNs. The feasibility of DeepSaucer is confirmed by implementing it on the basis of Anaconda, which provides virtual environment for loading a DNN and running a verification method. In addition, the effectiveness of DeepSaucer is demonstrated by usecase examples.