 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMood Classification of Bangla Songs Based on Lyrics
Jul 19, 2023



Music can evoke various emotions, and with the advancement of technology, it has become more accessible to people. Bangla music, which portrays different human emotions, lacks sufficient research. The authors of this article aim to analyze Bangla songs and classify their moods based on the lyrics. To achieve this, this research has compiled a dataset of 4000 Bangla song lyrics, genres, and used Natural Language Processing and the Bert Algorithm to analyze the data. Among the 4000 songs, 1513 songs are represented for the sad mood, 1362 for the romantic mood, 886 for happiness, and the rest 239 are classified as relaxation. By embedding the lyrics of the songs, the authors have classified the songs into four moods: Happy, Sad, Romantic, and Relaxed. This research is crucial as it enables a multi-class classification of songs' moods, making the music more relatable to people's emotions. The article presents the automated result of the four moods accurately derived from the song lyrics.
TextMage: The Automated Bangla Caption Generator Based On Deep Learning
Oct 15, 2020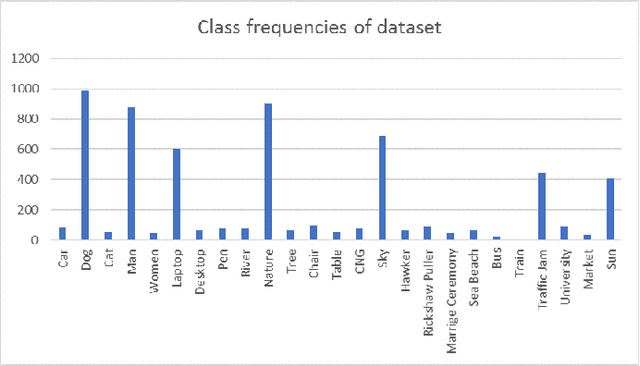
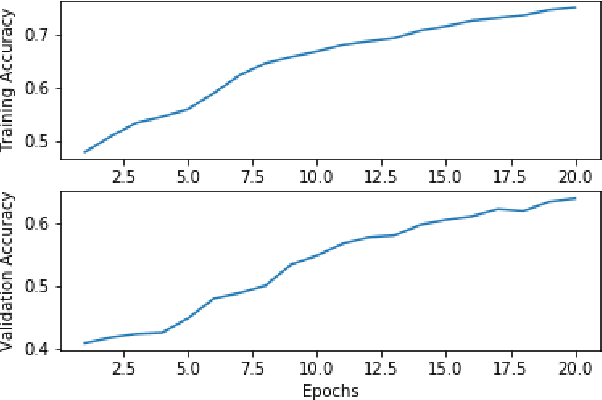
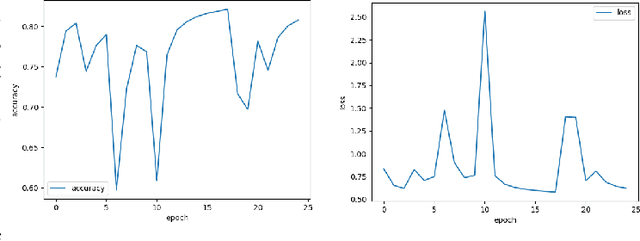
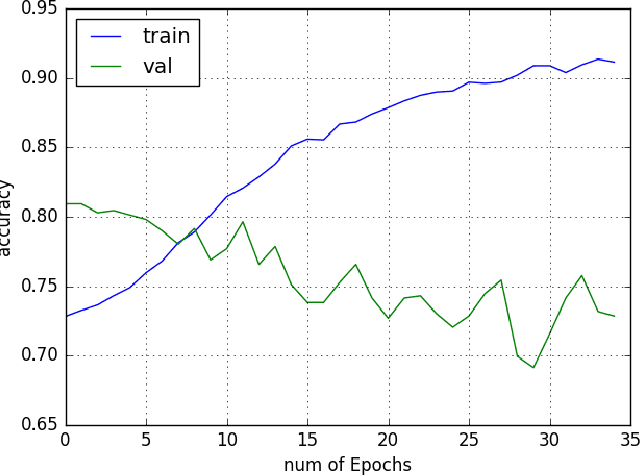
Neural Networks and Deep Learning have seen an upsurge of research in the past decade due to the improved results. Generates text from the given image is a crucial task that requires the combination of both sectors which are computer vision and natural language processing in order to understand an image and represent it using a natural language. However existing works have all been done on a particular lingual domain and on the same set of data. This leads to the systems being developed to perform poorly on images that belong to specific locales' geographical context. TextMage is a system that is capable of understanding visual scenes that belong to the Bangladeshi geographical context and use its knowledge to represent what it understands in Bengali. Hence, we have trained a model on our previously developed and published dataset named BanglaLekhaImageCaptions. This dataset contains 9,154 images along with two annotations for each image. In order to access performance, the proposed model has been implemented and evaluated.
Chittron: An Automatic Bangla Image Captioning System
Sep 02, 2018



Automatic image caption generation aims to produce an accurate description of an image in natural language automatically. However, Bangla, the fifth most widely spoken language in the world, is lagging considerably in the research and development of such domain. Besides, while there are many established data sets to related to image annotation in English, no such resource exists for Bangla yet. Hence, this paper outlines the development of "Chittron", an automatic image captioning system in Bangla. Moreover, to address the data set availability issue, a collection of 16,000 Bangladeshi contextual images has been accumulated and manually annotated in Bangla. This data set is then used to train a model which integrates a pre-trained VGG16 image embedding model with stacked LSTM layers. The model is trained to predict the caption when the input is an image, one word at a time. The results show that the model has successfully been able to learn a working language model and to generate captions of images quite accurately in many cases. The results are evaluated mainly qualitatively. However, BLEU scores are also reported. It is expected that a better result can be obtained with a bigger and more varied data set.