 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable and Semi-stable Sampling Approaches for Continuously Used Samples
Mar 02, 2022
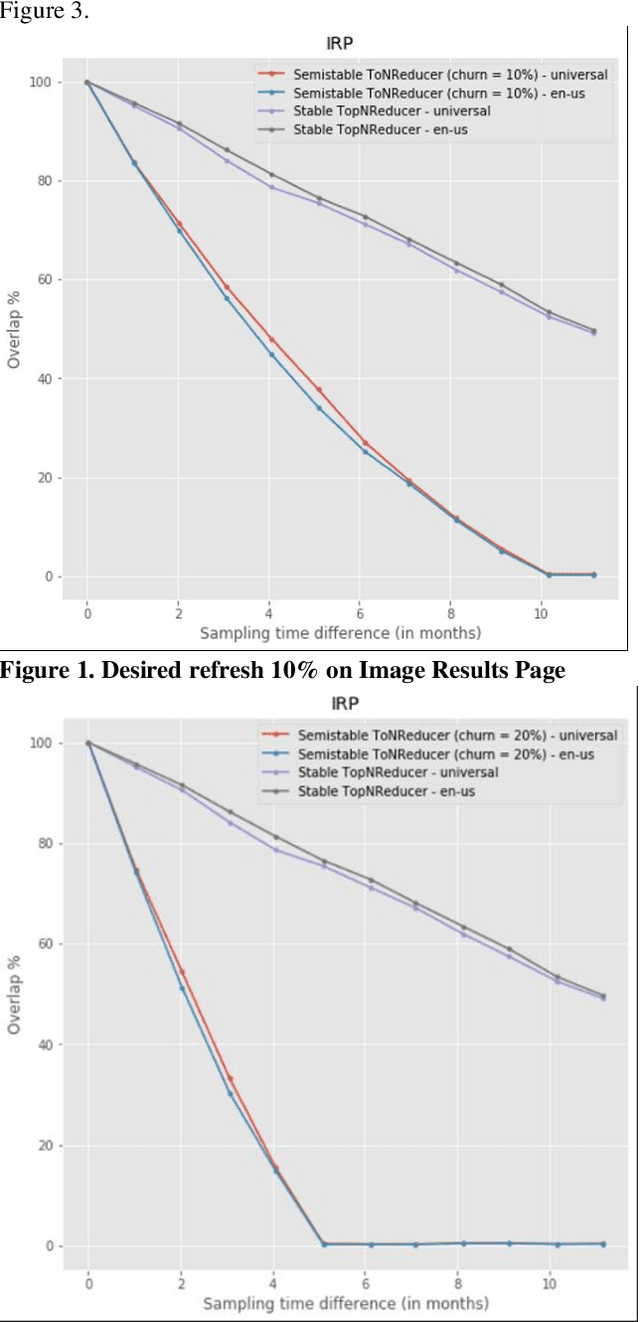
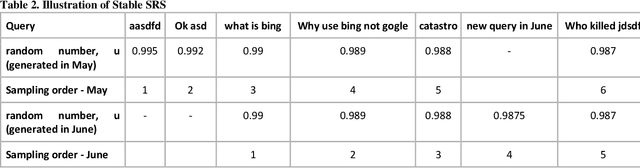
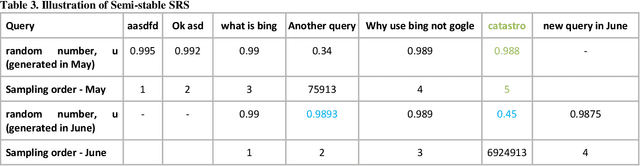
Information retrieval systems are usually measured by labeling the relevance of results corresponding to a sample of user queries. In practical search engines, such measurement needs to be performed continuously, such as daily or weekly. This creates a trade-off between (a) representativeness of query sample to current query traffic of the product; (b) labeling cost: if we keep the same query sample, results would be similar allowing us to reuse their labels; and (c) overfitting caused by continuous usage of same query sample. In this paper we explicitly formulate this tradeoff, propose two new variants -- Stable and Semi-stable -- to simple and weighted random sampling and show that they outperform existing approaches for the continuous usage settings, including monitoring/debugging search engine or comparing ranker candidates.