 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Data collection and implementation of deep learning-based model in detecting Monkeypox disease using modified VGG16
Jun 04, 2022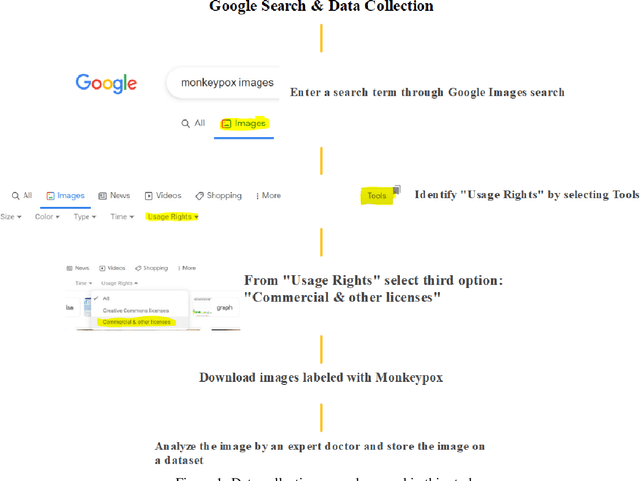
While the world is still attempting to recover from the damage caused by the broad spread of COVID-19, the Monkeypox virus poses a new threat of becoming a global pandemic. Although the Monkeypox virus itself is not deadly and contagious as COVID-19, still every day, new patients case has been reported from many nations. Therefore, it will be no surprise if the world ever faces another global pandemic due to the lack of proper precautious steps. Recently, Machine learning (ML) has demonstrated huge potential in image-based diagnoses such as cancer detection, tumor cell identification, and COVID-19 patient detection. Therefore, a similar application can be adopted to diagnose the Monkeypox-related disease as it infected the human skin, which image can be acquired and further used in diagnosing the disease. Considering this opportunity, in this work, we introduce a newly developed "Monkeypox2022" dataset that is publicly available to use and can be obtained from our shared GitHub repository. The dataset is created by collecting images from multiple open-source and online portals that do not impose any restrictions on use, even for commercial purposes, hence giving a safer path to use and disseminate such data when constructing and deploying any type of ML model. Further, we propose and evaluate a modified VGG16 model, which includes two distinct studies: Study One and Two. Our exploratory computational results indicate that our suggested model can identify Monkeypox patients with an accuracy of $97\pm1.8\%$ (AUC=97.2) and $88\pm0.8\%$ (AUC=0.867) for Study One and Two, respectively. Additionally, we explain our model's prediction and feature extraction utilizing Local Interpretable Model-Agnostic Explanations (LIME) help to a deeper insight into specific features that characterize the onset of the Monkeypox virus.
Monkeypox Image Data collection
Jun 03, 2022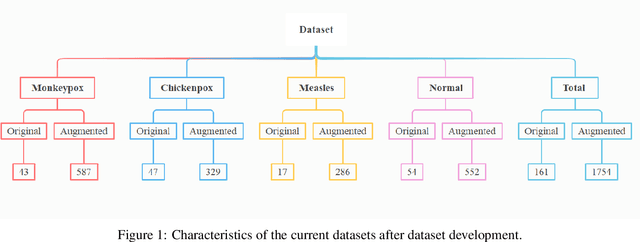

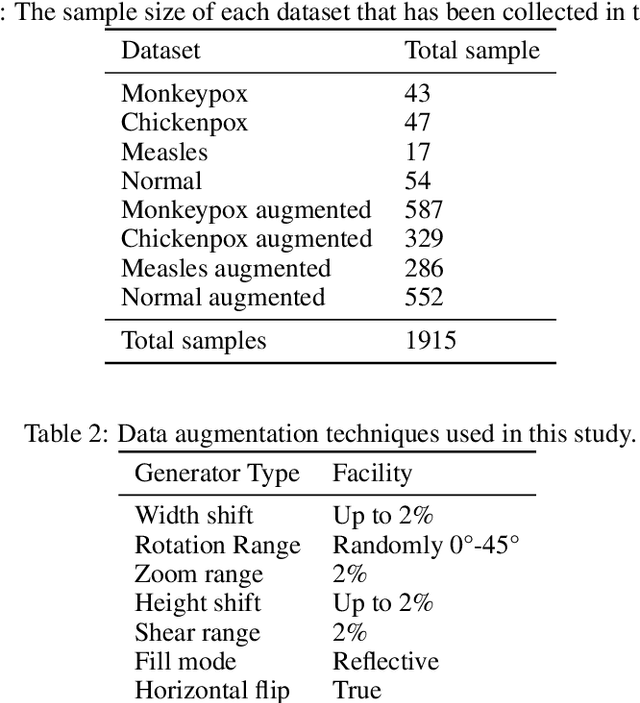
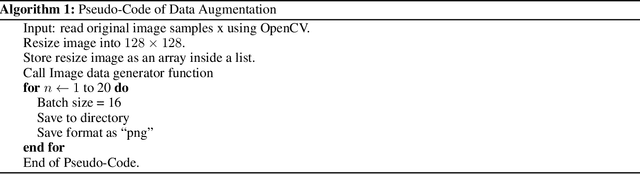
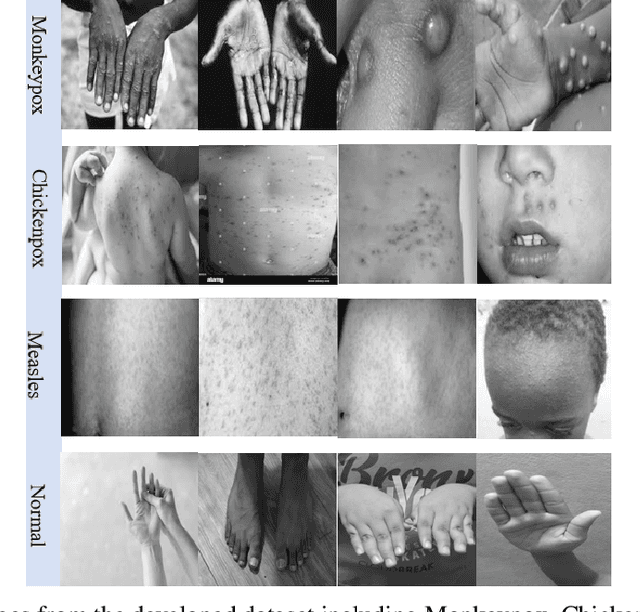
This paper explains the initial Monkeypox Open image data collection procedure. It was created by assembling images collected from websites, newspapers, and online portals and currently contains around 1905 images after data augmentation.