 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Spoken Dialog Systems in Ultra-Low Resourced Settings
Dec 11, 2023Automatic Speech Recognition (ASR) systems are a crucial technology that is used today to design a wide variety of applications, most notably, smart assistants, such as Alexa. ASR systems are essentially dialogue systems that employ Spoken Language Understanding (SLU) to extract meaningful information from speech. The main challenge with designing such systems is that they require a huge amount of labeled clean data to perform competitively, such data is extremely hard to collect and annotate to respective SLU tasks, furthermore, when designing such systems for low resource languages, where data is extremely limited, the severity of the problem intensifies. In this paper, we focus on a fairly popular SLU task, that is, Intent Classification while working with a low resource language, namely, Flemish. Intent Classification is a task concerned with understanding the intents of the user interacting with the system. We build on existing light models for intent classification in Flemish, and our main contribution is applying different augmentation techniques on two levels -- the voice level, and the phonetic transcripts level -- to the existing models to counter the problem of scarce labeled data in low-resource languages. We find that our data augmentation techniques, on both levels, have improved the model performance on a number of tasks.
Modeling, Visualization, and Analysis of African Innovation Performance
Aug 18, 2020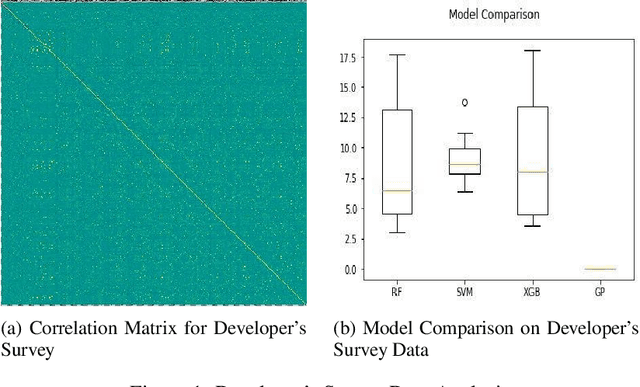
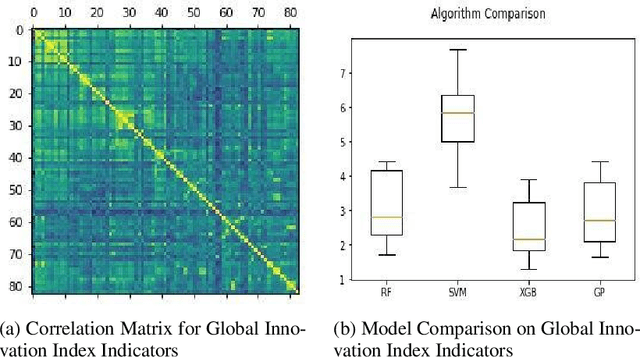
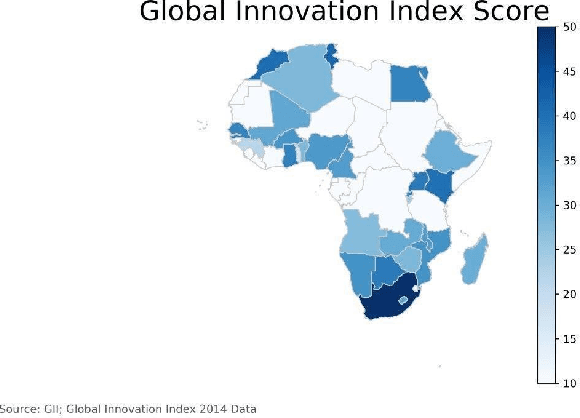
In this paper we discuss the concepts and emergence of Innovation Performance, and how to quantify it, primarily working with data from the Global Innovation Index, with emphasis on the African Innovation Performance. We briefly overview existing literature on using machine learning for modeling innovation performance, and use simple machine learning techniques, to analyze and predict the "Mobile App Creation Indicator" from the Global Innovation Index, by using insights from the stack-overflow developers survey. Also, we build and compare models to predict the Innovation Output Sub-index, also from the Global Innovation Index.