 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet your Foes Fooled: Proximal Gradient Split Learning for Defense against Model Inversion Attacks on IoMT data
Jan 20, 2022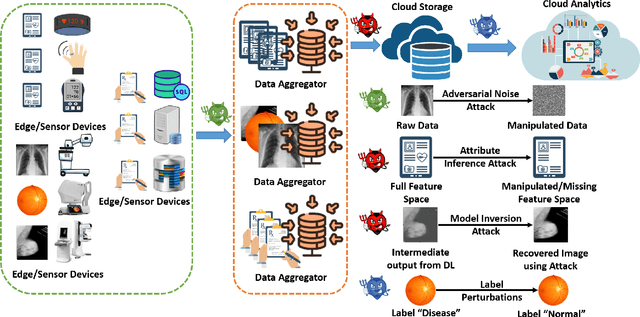
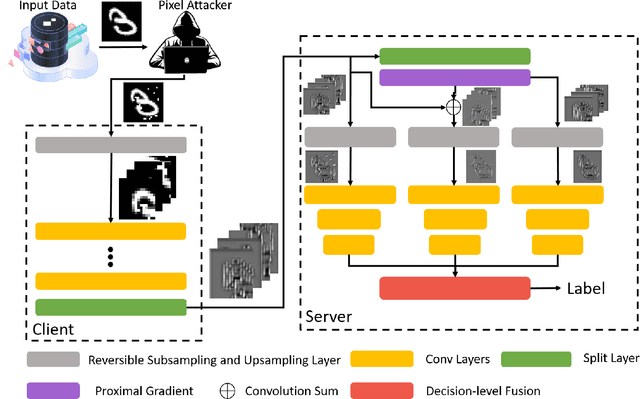
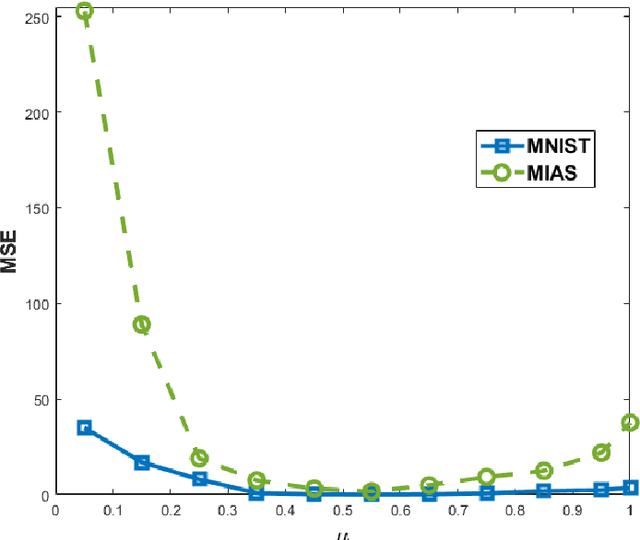

The past decade has seen a rapid adoption of Artificial Intelligence (AI), specifically the deep learning networks, in Internet of Medical Things (IoMT) ecosystem. However, it has been shown recently that the deep learning networks can be exploited by adversarial attacks that not only make IoMT vulnerable to the data theft but also to the manipulation of medical diagnosis. The existing studies consider adding noise to the raw IoMT data or model parameters which not only reduces the overall performance concerning medical inferences but also is ineffective to the likes of deep leakage from gradients method. In this work, we propose proximal gradient split learning (PSGL) method for defense against the model inversion attacks. The proposed method intentionally attacks the IoMT data when undergoing the deep neural network training process at client side. We propose the use of proximal gradient method to recover gradient maps and a decision-level fusion strategy to improve the recognition performance. Extensive analysis show that the PGSL not only provides effective defense mechanism against the model inversion attacks but also helps in improving the recognition performance on publicly available datasets. We report 17.9$\%$ and 36.9$\%$ gains in accuracy over reconstructed and adversarial attacked images, respectively.
Provenance, Anonymisation and Data Environments: a Unifying Construction
Jul 21, 2021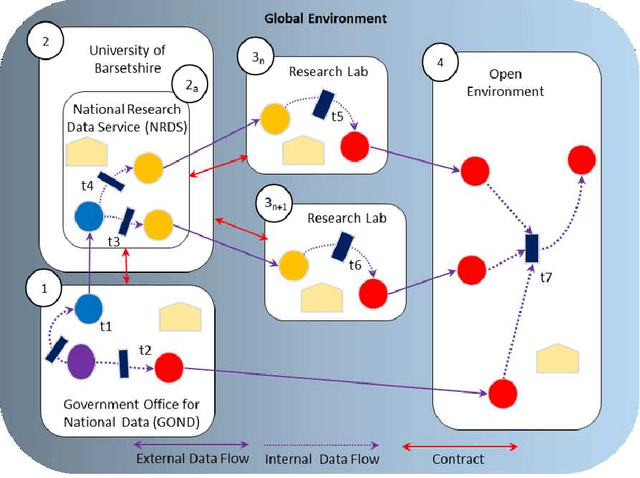



The Anonymisation Decision-making Framework (ADF) operationalizes the risk management of data exchange between organizations, referred to as "data environments". The second edition of ADF has increased its emphasis on modeling data flows, highlighting a potential new use of provenance information to support anonymisation decision-making. In this paper, we provide a use case that showcases this functionality more. Based on this use case, we identify how provenance information could be utilized within the ADF framework, and identify a currently un-met requirement which is the modeling of \textit{data environments}. We show how data environments can be implemented within the W3C PROV in four different ways. We analyze the costs and benefits of each approach, and consider another use case as a partial check for completeness. We then summarize our findings and suggest ways forward.
Microservices based Framework to Support Interoperable IoT Applications for Enhanced Data Analytics
Oct 19, 2019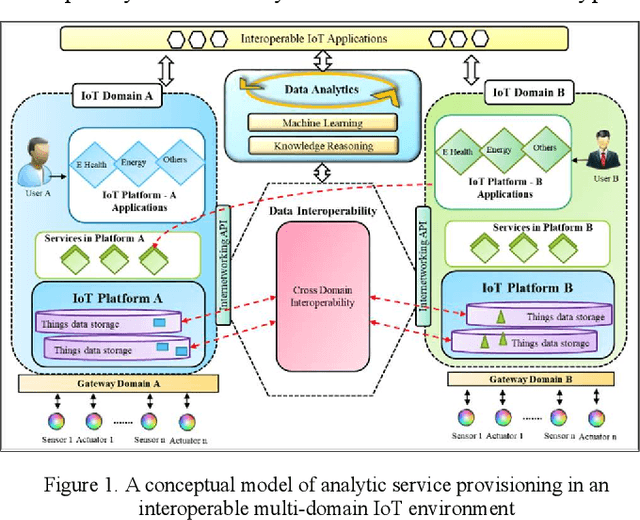
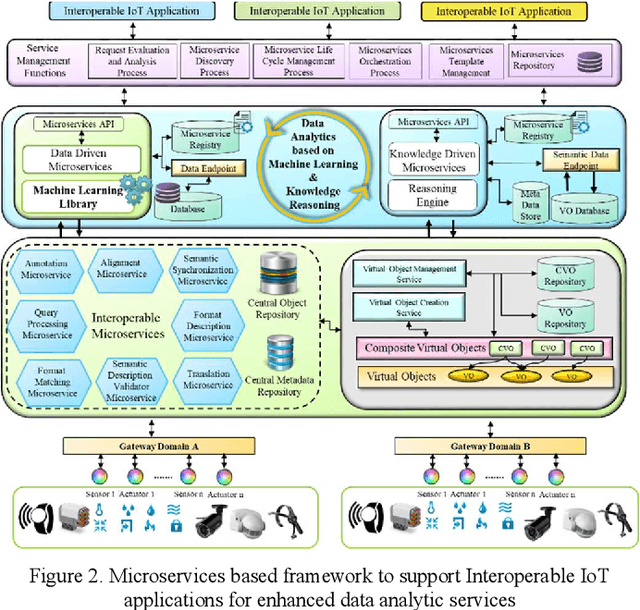
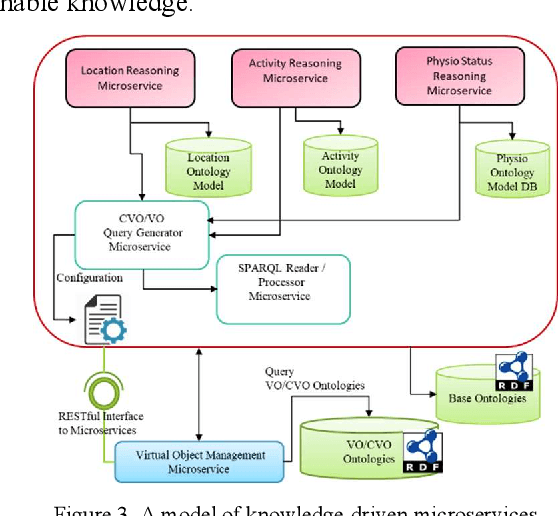
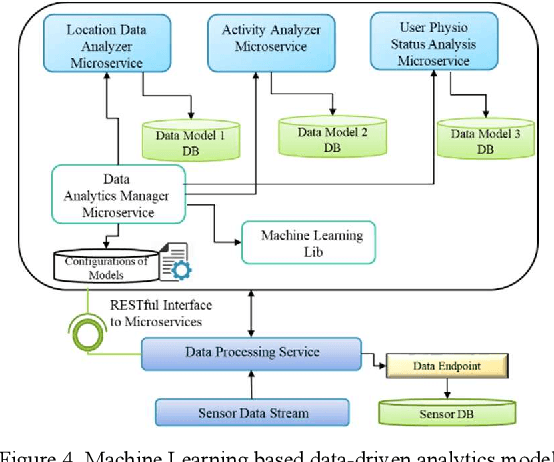
Internet of things is growing with a large number of diverse objects which generate billions of data streams by sensing, actuating and communicating. Management of heterogeneous IoT objects with existing approaches and processing of myriads of data from these objects using monolithic services have become major challenges in developing effective IoT applications. The heterogeneity can be resolved by providing interoperability with semantic virtualization of objects. Moreover, monolithic services can be substituted with modular microservices. This article presents an architecture that enables the development of IoT applications using semantically interoperable microservices and virtual objects. The proposed framework supports analytic features with knowledge-driven and data-driven techniques to provision intelligent services on top of interoperable microservices in Web Objects enabled IoT environment. The knowledge-driven aspects are supported with reasoning on semantic ontology models and the data-driven aspects are realized with machine learning pipeline. The development of service functionalities is supported with microservices to enhance modularity and reusability. To evaluate the proposed framework a proof of concept implementation with a use case is discussed.
A Framework for Detecting Event related Sentiments of a Community
Mar 01, 2019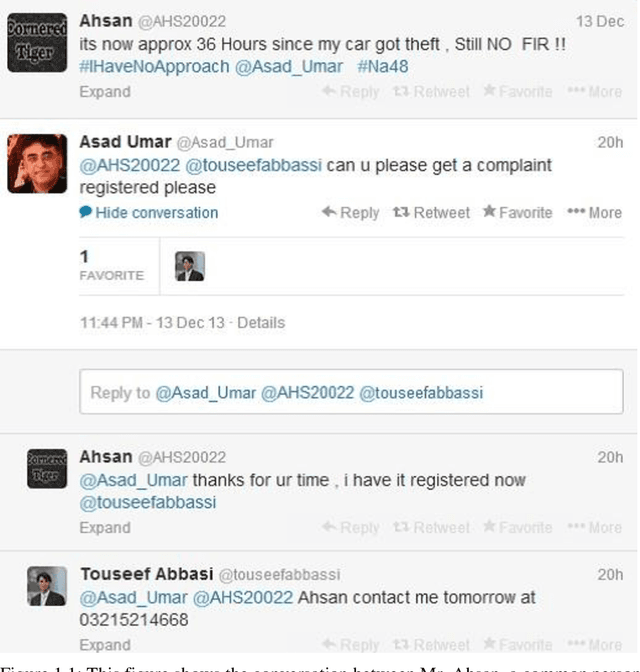

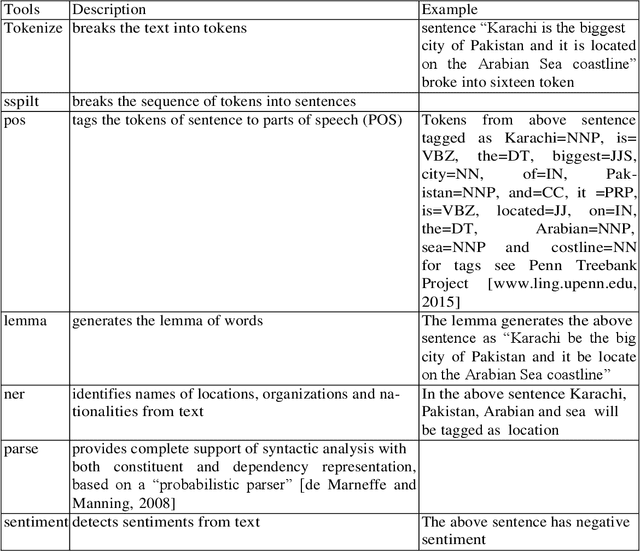
Social media has revolutionized human communication and styles of interaction. Due to its easiness and effective medium, people share and exchange information, carry out discussion on various events, and express their opinions. For effective policy making and understanding the response of a community on different events, we need to monitor and analyze the social media. In social media, there are some users who are more influential, for example, a famous politician may have more influence than a common person. These influential users belong to specific communities. The main object of this research is to know the sentiments of a specific community on various events. For detecting the event based sentiments of a community we propose a generic framework. Our framework identifies the users of a specific community on twitter. After identifying the users of a community, we fetch their tweets and identify tweets belonging to specific events. The event based tweets are pre-processed. Pre-processed tweets are then analyzed for detecting sentiments of a community for specific events. Qualitative and quantitative evaluation confirms the effectiveness and usefulness of our proposed framework.