 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag-based Multi-Span Extraction in Reading Comprehension
Oct 02, 2019
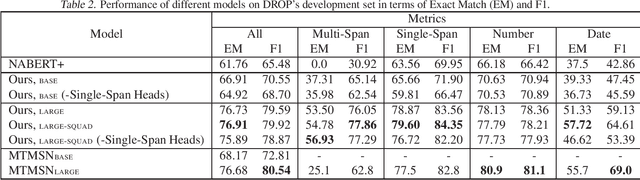
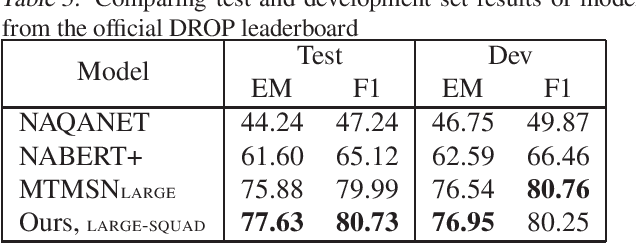
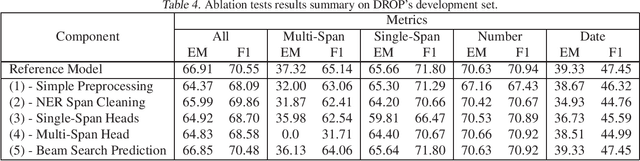
With models reaching human performance on many popular reading comprehension datasets in recent years, a new dataset, DROP, introduced questions that were expected to present a harder challenge for reading comprehension models. Among these new types of questions were "multi-span questions", questions whose answers consist of several spans from either the paragraph or the question itself. Until now, only one model attempted to tackle multi-span questions as a part of its design. In this work, we suggest a new approach for tackling multi-span questions, based on sequence tagging, which differs from previous approaches for answering span questions. We show that our approach leads to an absolute improvement of 29.7 EM and 15.1 F1 compared to existing state-of-the-art results, while not hurting performance on other question types. Furthermore, we show that our model slightly eclipses the current state-of-the-art results on the entire DROP dataset.