 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhitespaces Don't Lie: Feature-Driven and Embedding-Based Approaches for Detecting Machine-Generated Code
Jan 27, 2026Large language models (LLMs) have made it remarkably easy to synthesize plausible source code from natural language prompts. While this accelerates software development and supports learning, it also raises new risks for academic integrity, authorship attribution, and responsible AI use. This paper investigates the problem of distinguishing human-written from machine-generated code by comparing two complementary approaches: feature-based detectors built from lightweight, interpretable stylometric and structural properties of code, and embedding-based detectors leveraging pretrained code encoders. Using a recent large-scale benchmark dataset of 600k human-written and AI-generated code samples, we find that feature-based models achieve strong performance (ROC-AUC 0.995, PR-AUC 0.995, F1 0.971), while embedding-based models with CodeBERT embeddings are also very competitive (ROC-AUC 0.994, PR-AUC 0.994, F1 0.965). Analysis shows that features tied to indentation and whitespace provide particularly discriminative cues, whereas embeddings capture deeper semantic patterns and yield slightly higher precision. These findings underscore the trade-offs between interpretability and generalization, offering practical guidance for deploying robust code-origin detection in academic and industrial contexts.
Handcrafted Feature Fusion for Reliable Detection of AI-Generated Images
Jan 27, 2026The rapid progress of generative models has enabled the creation of highly realistic synthetic images, raising concerns about authenticity and trust in digital media. Detecting such fake content reliably is an urgent challenge. While deep learning approaches dominate current literature, handcrafted features remain attractive for their interpretability, efficiency, and generalizability. In this paper, we conduct a systematic evaluation of handcrafted descriptors, including raw pixels, color histograms, Discrete Cosine Transform (DCT), Histogram of Oriented Gradients (HOG), Local Binary Patterns (LBP), Gray-Level Co-occurrence Matrix (GLCM), and wavelet features, on the CIFAKE dataset of real versus synthetic images. Using 50,000 training and 10,000 test samples, we benchmark seven classifiers ranging from Logistic Regression to advanced gradient-boosted ensembles (LightGBM, XGBoost, CatBoost). Results demonstrate that LightGBM consistently outperforms alternatives, achieving PR-AUC 0.9879, ROC-AUC 0.9878, F1 0.9447, and a Brier score of 0.0414 with mixed features, representing strong gains in calibration and discrimination over simpler descriptors. Across three configurations (baseline, advanced, mixed), performance improves monotonically, confirming that combining diverse handcrafted features yields substantial benefit. These findings highlight the continued relevance of carefully engineered features and ensemble learning for detecting synthetic images, particularly in contexts where interpretability and computational efficiency are critical.
Predicting skull fractures via CNN with classification algorithms
Aug 14, 2022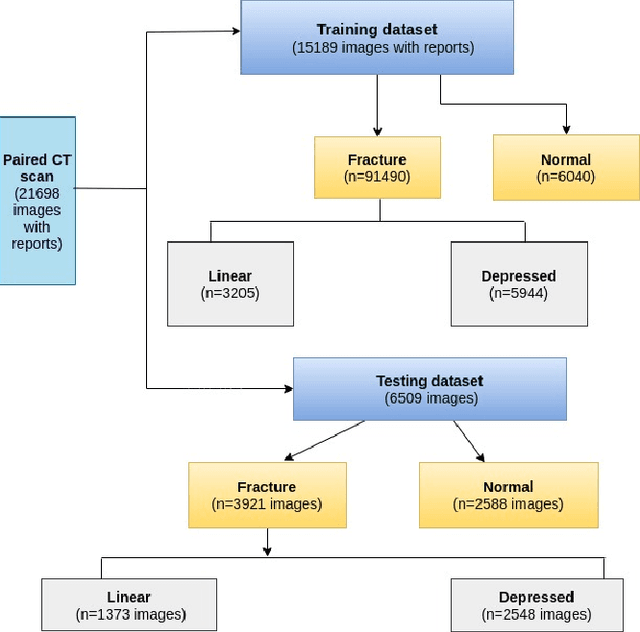
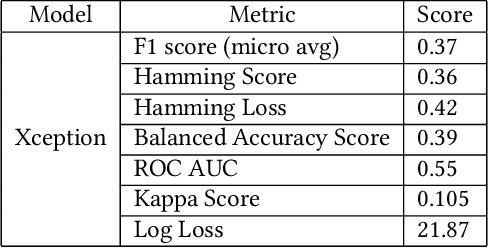
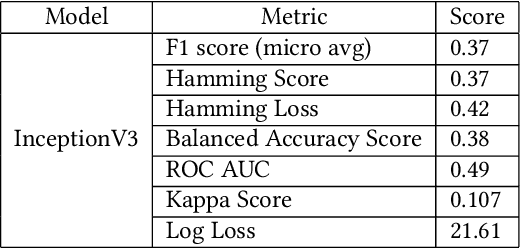
Computer Tomography (CT) images have become quite important to diagnose diseases. CT scan slice contains a vast amount of data that may not be properly examined with the requisite precision and speed using normal visual inspection. A computer-assisted skull fracture classification expert system is needed to assist physicians. Convolutional Neural Networks (CNNs) are the most extensively used deep learning models for image categorization since most often time they outperform other models in terms of accuracy and results. The CNN models were then developed and tested, and several convolutional neural network (CNN) architectures were compared. ResNet50, which was used for feature extraction combined with a gradient boosted decision tree machine learning algorithm to act as a classifier for the categorization of skull fractures from brain CT scans into three fracture categories, had the best overall F1-score of 96%, Hamming Score of 95%, Balanced accuracy Score of 94% & ROC AUC curve of 96% for the classification of skull fractures.
Classifications of Skull Fractures using CT Scan Images via CNN with Lazy Learning Approach
Mar 21, 2022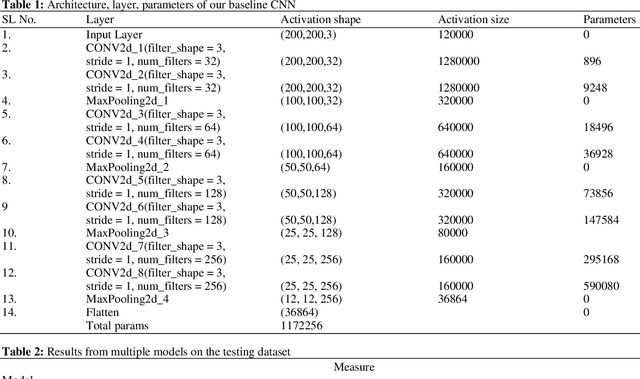
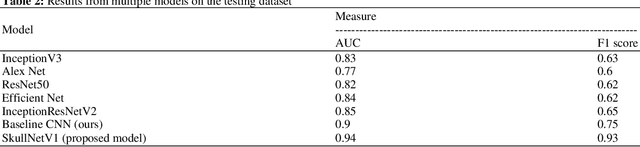
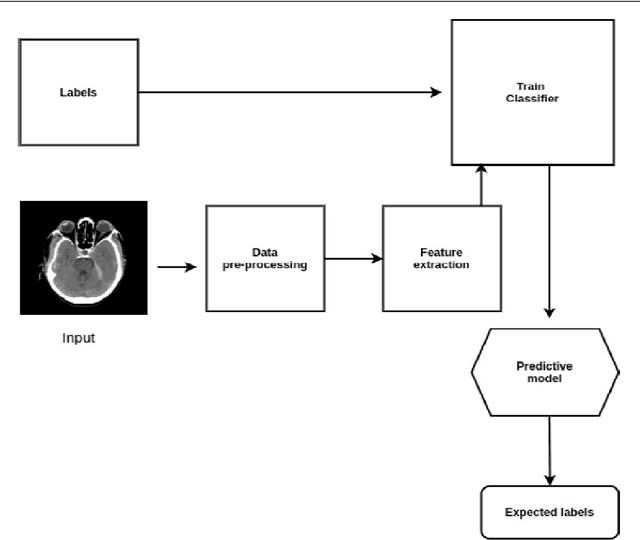
Classification of skull fracture is a challenging task for both radiologists and researchers. Skull fractures result in broken pieces of bone, which can cut into the brain and cause bleeding and other injury types. So it is vital to detect and classify the fracture very early. In real world, often fractures occur at multiple sites. This makes it harder to detect the fracture type where many fracture types might summarize a skull fracture. Unfortunately, manual detection of skull fracture and the classification process is time-consuming, threatening a patient's life. Because of the emergence of deep learning, this process could be automated. Convolutional Neural Networks (CNNs) are the most widely used deep learning models for image categorization because they deliver high accuracy and outstanding outcomes compared to other models. We propose a new model called SkullNetV1 comprising a novel CNN by taking advantage of CNN for feature extraction and lazy learning approach which acts as a classifier for classification of skull fractures from brain CT images to classify five fracture types. Our suggested model achieved a subset accuracy of 88%, an F1 score of 93%, the Area Under the Curve (AUC) of 0.89 to 0.98, a Hamming score of 92% and a Hamming loss of 0.04 for this seven-class multi-labeled classification.