 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-learning-based particle identification with missing data
Dec 21, 2023In this work, we introduce a novel method for Particle Identification (PID) within the scope of the ALICE experiment at the Large Hadron Collider at CERN. Identifying products of ultrarelativisitc collisions delivered by the LHC is one of the crucial objectives of ALICE. Typically employed PID methods rely on hand-crafted selections, which compare experimental data to theoretical simulations. To improve the performance of the baseline methods, novel approaches use machine learning models that learn the proper assignment in a classification task. However, because of the various detection techniques used by different subdetectors, as well as the limited detector efficiency and acceptance, produced particles do not always yield signals in all of the ALICE components. This results in data with missing values. Machine learning techniques cannot be trained with such examples, so a significant part of the data is skipped during training. In this work, we propose the first method for PID that can be trained with all of the available data examples, including incomplete ones. Our approach improves the PID purity and efficiency of the selected sample for all investigated particle species.
Using Machine Learning for Particle Identification in ALICE
Apr 14, 2022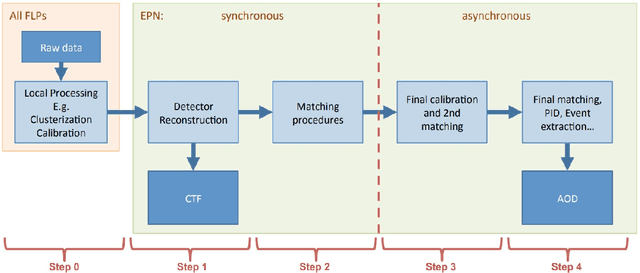

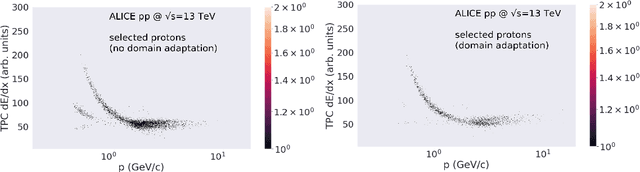
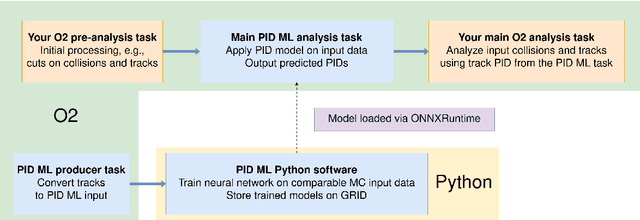
Particle identification (PID) is one of the main strengths of the ALICE experiment at the LHC. It is a crucial ingredient for detailed studies of the strongly interacting matter formed in ultrarelativistic heavy-ion collisions. ALICE provides PID information via various experimental techniques, allowing for the identification of particles over a broad momentum range (from around 100 MeV/$c$ to around 50 GeV/$c$). The main challenge is how to combine the information from various detectors effectively. Therefore, PID represents a model classification problem, which can be addressed using Machine Learning (ML) solutions. Moreover, the complexity of the detector and richness of the detection techniques make PID an interesting area of research also for the computer science community. In this work, we show the current status of the ML approach to PID in ALICE. We discuss the preliminary work with the Random Forest approach for the LHC Run 2 and a more advanced solution based on Domain Adaptation Neural Networks, including a proposal for its future implementation within the ALICE computing software for the upcoming LHC Run 3.