 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRumor Detection and Classification for Twitter Data
Nov 25, 2019
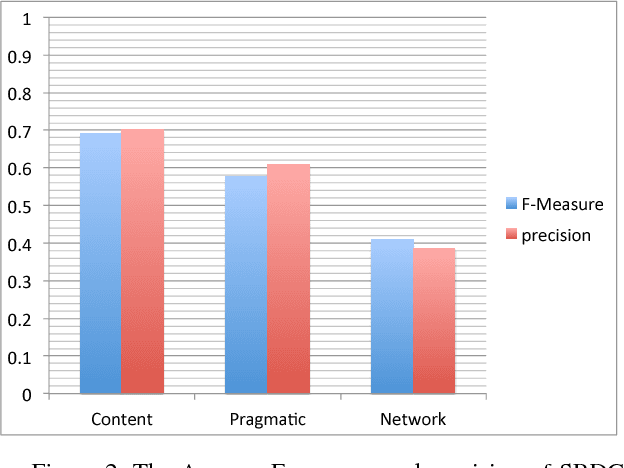
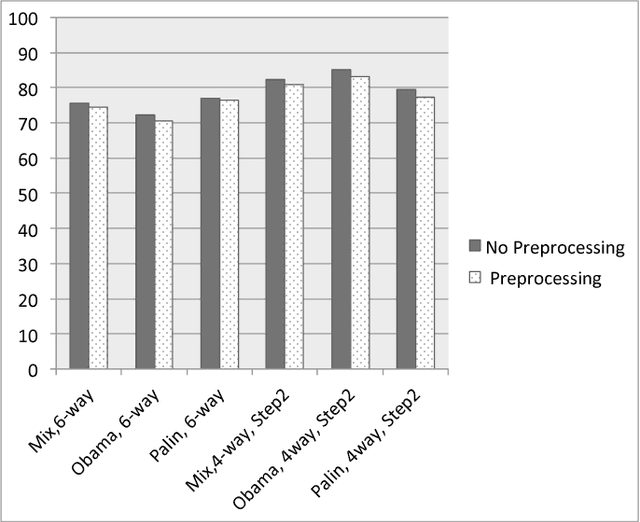

With the pervasiveness of online media data as a source of information verifying the validity of this information is becoming even more important yet quite challenging. Rumors spread a large quantity of misinformation on microblogs. In this study we address two common issues within the context of microblog social media. First we detect rumors as a type of misinformation propagation and next we go beyond detection to perform the task of rumor classification. WE explore the problem using a standard data set. We devise novel features and study their impact on the task. We experiment with various levels of preprocessing as a precursor of the classification as well as grouping of features. We achieve and f-measure of over 0.82 in RDC task in mixed rumors data set and 84 percent in a single rumor data set using a two-step classification approach.