 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn enhanced Teaching-Learning-Based Optimization (TLBO) with Grey Wolf Optimizer (GWO) for text feature selection and clustering
Feb 19, 2024



Text document clustering can play a vital role in organizing and handling the everincreasing number of text documents. Uninformative and redundant features included in large text documents reduce the effectiveness of the clustering algorithm. Feature selection (FS) is a well-known technique for removing these features. Since FS can be formulated as an optimization problem, various meta-heuristic algorithms have been employed to solve it. Teaching-Learning-Based Optimization (TLBO) is a novel meta-heuristic algorithm that benefits from the low number of parameters and fast convergence. A hybrid method can simultaneously benefit from the advantages of TLBO and tackle the possible entrapment in the local optimum. By proposing a hybrid of TLBO, Grey Wolf Optimizer (GWO), and Genetic Algorithm (GA) operators, this paper suggests a filter-based FS algorithm (TLBO-GWO). Six benchmark datasets are selected, and TLBO-GWO is compared with three recently proposed FS algorithms with similar approaches, the main TLBO and GWO. The comparison is conducted based on clustering evaluation measures, convergence behavior, and dimension reduction, and is validated using statistical tests. The results reveal that TLBO-GWO can significantly enhance the effectiveness of the text clustering technique (K-means).
A Novel Bio-Inspired Hybrid Multi-Filter Wrapper Gene Selection Method with Ensemble Classifier for Microarray Data
Jan 04, 2021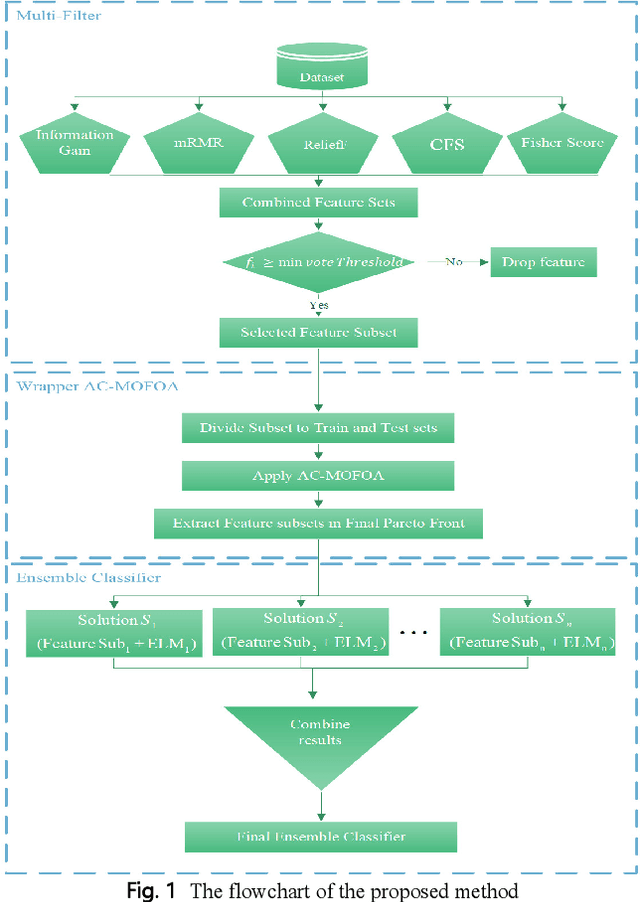
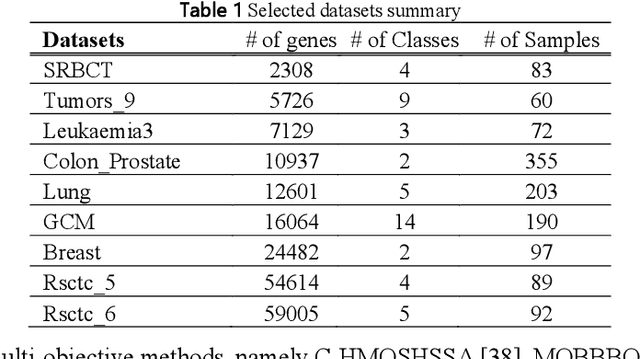

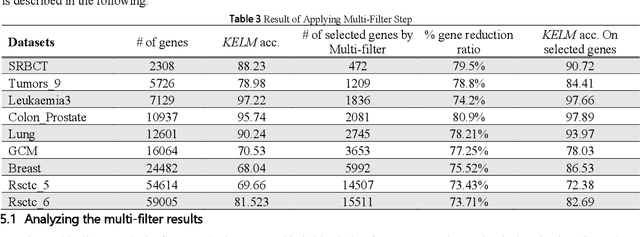
Microarray technology is known as one of the most important tools for collecting DNA expression data. This technology allows researchers to investigate and examine types of diseases and their origins. However, microarray data are often associated with challenges such as small sample size, a significant number of genes, imbalanced data, etc. that make classification models inefficient. Thus, a new hybrid solution based on multi-filter and adaptive chaotic multi-objective forest optimization algorithm (AC-MOFOA) is presented to solve the gene selection problem and construct the Ensemble Classifier. In the proposed solution, to reduce the dataset's dimensions, a multi-filter model uses a combination of five filter methods to remove redundant and irrelevant genes. Then, an AC-MOFOA based on the concepts of non-dominated sorting, crowding distance, chaos theory, and adaptive operators is presented. AC-MOFOA as a wrapper method aimed at reducing dataset dimensions, optimizing KELM, and increasing the accuracy of the classification, simultaneously. Next, in this method, an ensemble classifier model is presented using AC-MOFOA results to classify microarray data. The performance of the proposed algorithm was evaluated on nine public microarray datasets, and its results were compared in terms of the number of selected genes, classification efficiency, execution time, time complexity, and hypervolume indicator criterion with five hybrid multi-objective methods. According to the results, the proposed hybrid method could increase the accuracy of the KELM in most datasets by reducing the dataset's dimensions and achieve similar or superior performance compared to other multi-objective methods. Furthermore, the proposed Ensemble Classifier model could provide better classification accuracy and generalizability in microarray data compared to conventional ensemble methods.