Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualWordGrid: Information Extraction From Scanned Documents Using A Multimodal Approach
Oct 13, 2020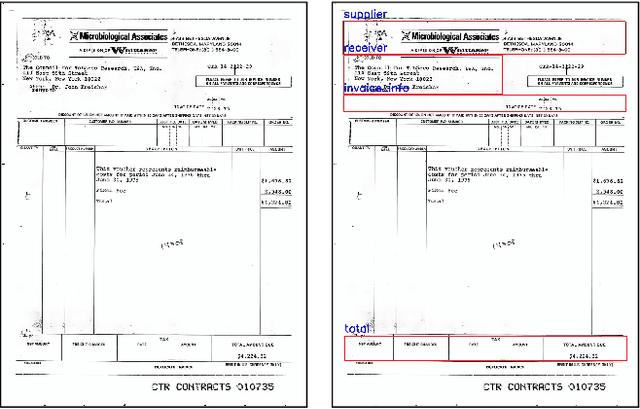

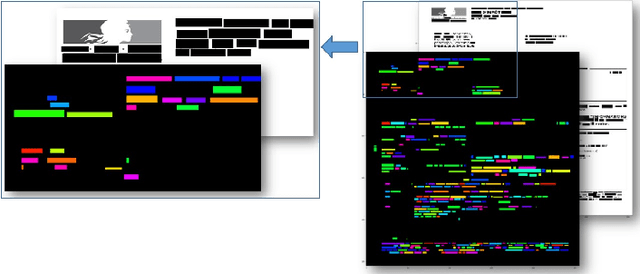
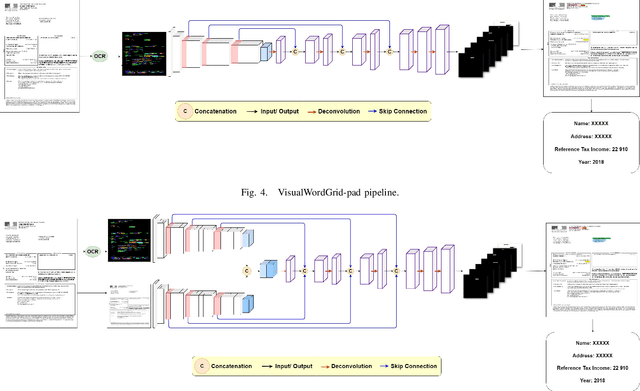
We introduce a novel approach for scanned document representation to perform field extraction. It allows the simultaneous encoding of the textual, visual and layout information in a 3D matrix used as an input to a segmentation model. We improve the recent Chargrid and Wordgrid models in several ways, first by taking into account the visual modality, then by boosting its robustness in regards to small datasets while keeping the inference time low. Our approach is tested on public and private document-image datasets, showing higher performances compared to the recent state-of-the-art methods.
Via