 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Foundational Models and Simple Fusion for Multi-modal Physiological Signal Analysis
Dec 17, 2025Physiological signals such as electrocardiograms (ECG) and electroencephalograms (EEG) provide complementary insights into human health and cognition, yet multi-modal integration is challenging due to limited multi-modal labeled data, and modality-specific differences . In this work, we adapt the CBraMod encoder for large-scale self-supervised ECG pretraining, introducing a dual-masking strategy to capture intra- and inter-lead dependencies. To overcome the above challenges, we utilize a pre-trained CBraMod encoder for EEG and pre-train a symmetric ECG encoder, equipping each modality with a rich foundational representation. These representations are then fused via simple embedding concatenation, allowing the classification head to learn cross-modal interactions, together enabling effective downstream learning despite limited multi-modal supervision. Evaluated on emotion recognition, our approach achieves near state-of-the-art performance, demonstrating that carefully designed physiological encoders, even with straightforward fusion, substantially improve downstream performance. These results highlight the potential of foundation-model approaches to harness the holistic nature of physiological signals, enabling scalable, label-efficient, and generalizable solutions for healthcare and affective computing.
The Benefit of Noise-Injection for Dynamic Gray-Box Model Creation
Oct 02, 2023Gray-box models offer significant benefit over black-box approaches for equipment emulator development for equipment since their integration of physics provides more confidence in the model outside of the training domain. However, challenges such as model nonlinearity, unmodeled dynamics, and local minima introduce uncertainties into grey-box creation that contemporary approaches have failed to overcome, leading to their under-performance compared with black-box models. This paper seeks to address these uncertainties by injecting noise into the training dataset. This noise injection enriches the dataset and provides a measure of robustness against such uncertainties. A dynamic model for a water-to-water heat exchanger has been used as a demonstration case for this approach and tested using a pair of real devices with live data streaming. Compared to the unprocessed signal data, the application of noise injection resulted in a significant reduction in modeling error (root mean square error), decreasing from 0.68 to 0.27{\deg}C. This improvement amounts to a 60% enhancement when assessed on the training set, and improvements of 50% and 45% when validated against the test and validation sets, respectively.
Fault Detection for Non-Condensing Boilers using Simulated Building Automation System Sensor Data
May 13, 2022
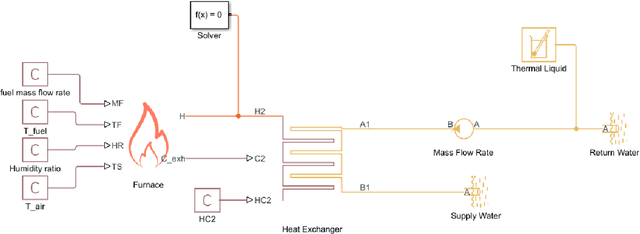
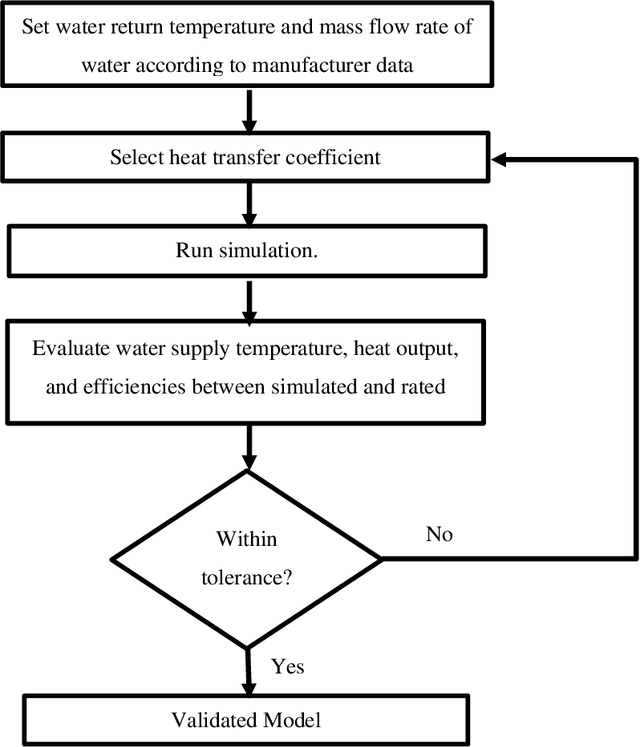

Building performance has been shown to degrade significantly after commissioning, resulting in increased energy consumption and associated greenhouse gas emissions. Continuous Commissioning using existing sensor networks and IoT devices has the potential to minimize this waste by continually identifying system degradation and re-tuning control strategies to adapt to real building performance. Due to its significant contribution to greenhouse gas emissions, the performance of gas boiler systems for building heating is critical. A review of boiler performance studies has been used to develop a set of common faults and degraded performance conditions, which have been integrated into a MATLAB/Simulink emulator. This resulted in a labeled dataset with approximately 10,000 simulations of steady-state performance for each of 14 non-condensing boilers. The collected data is used for training and testing fault classification using K-nearest neighbour, Decision tree, Random Forest, and Support Vector Machines. The results show that the Support Vector Machines method gave the best prediction accuracy, consistently exceeding 90%, and generalization across multiple boilers is not possible due to low classification accuracy.