 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIBE: Visual Instruction Based Editor
Jan 05, 2026Instruction-based image editing is among the fastest developing areas in generative AI. Over the past year, the field has reached a new level, with dozens of open-source models released alongside highly capable commercial systems. However, only a limited number of open-source approaches currently achieve real-world quality. In addition, diffusion backbones, the dominant choice for these pipelines, are often large and computationally expensive for many deployments and research settings, with widely used variants typically containing 6B to 20B parameters. This paper presents a compact, high-throughput instruction-based image editing pipeline that uses a modern 2B-parameter Qwen3-VL model to guide the editing process and the 1.6B-parameter diffusion model Sana1.5 for image generation. Our design decisions across architecture, data processing, training configuration, and evaluation target low-cost inference and strict source consistency while maintaining high quality across the major edit categories feasible at this scale. Evaluated on the ImgEdit and GEdit benchmarks, the proposed method matches or exceeds the performance of substantially heavier baselines, including models with several times as many parameters and higher inference cost, and is particularly strong on edits that require preserving the input image, such as an attribute adjustment, object removal, background edits, and targeted replacement. The model fits within 24 GB of GPU memory and generates edited images at up to 2K resolution in approximately 4 seconds on an NVIDIA H100 in BF16, without additional inference optimizations or distillation.
CerberusDet: Unified Multi-Task Object Detection
Jul 17, 2024


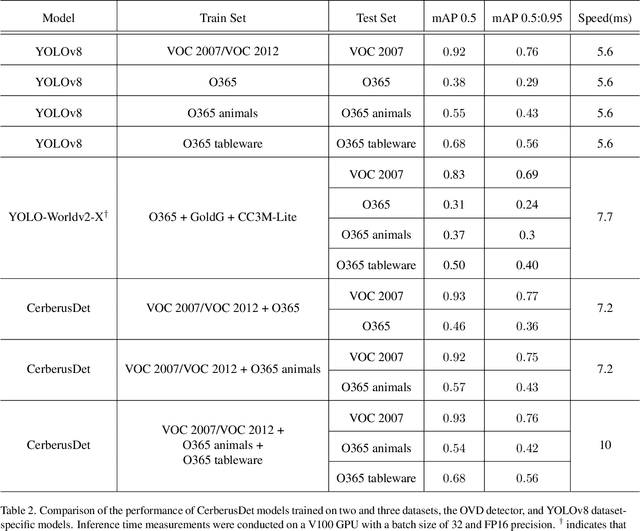
Object detection is a core task in computer vision. Over the years, the development of numerous models has significantly enhanced performance. However, these conventional models are usually limited by the data on which they were trained and by the category logic they define. With the recent rise of Language-Visual Models, new methods have emerged that are not restricted to these fixed categories. Despite their flexibility, such Open Vocabulary detection models still fall short in accuracy compared to traditional models with fixed classes. At the same time, more accurate data-specific models face challenges when there is a need to extend classes or merge different datasets for training. The latter often cannot be combined due to different logics or conflicting class definitions, making it difficult to improve a model without compromising its performance. In this paper, we introduce CerberusDet, a framework with a multi-headed model designed for handling multiple object detection tasks. Proposed model is built on the YOLO architecture and efficiently shares visual features from both backbone and neck components, while maintaining separate task heads. This approach allows CerberusDet to perform very efficiently while still delivering optimal results. We evaluated the model on the PASCAL VOC dataset and additional categories from the Objects365 dataset to demonstrate its abilities. CerberusDet achieved results comparable to state-of-the-art data-specific models with 36% less inference time. The more tasks are trained together, the more efficient the proposed model becomes compared to running individual models sequentially. The training and inference code, as well as the model, are available as open-source (https://github.com/ai-forever/CerberusDet).