 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Network Model of Lexical Competition during Infant Spoken Word Recognition
Jun 01, 2020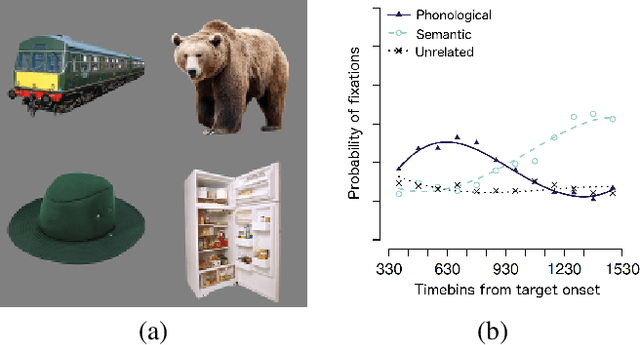

Visual world studies show that upon hearing a word in a target-absent visual context containing related and unrelated items, toddlers and adults briefly direct their gaze towards phonologically related items, before shifting towards semantically and visually related ones. We present a neural network model that processes dynamic unfolding phonological representations and maps them to static internal semantic and visual representations. The model, trained on representations derived from real corpora, simulates this early phonological over semantic/visual preference. Our results support the hypothesis that incremental unfolding of a spoken word is in itself sufficient to account for the transient preference for phonological competitors over both unrelated and semantically and visually related ones. Phonological representations mapped dynamically in a bottom-up fashion to semantic-visual representations capture the early phonological preference effects reported in a visual world task. The semantic-visual preference observed later in such a trial does not require top-down feedback from a semantic or visual system.