 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCebuaNER: A New Baseline Cebuano Named Entity Recognition Model
Oct 01, 2023Despite being one of the most linguistically diverse groups of countries, computational linguistics and language processing research in Southeast Asia has struggled to match the level of countries from the Global North. Thus, initiatives such as open-sourcing corpora and the development of baseline models for basic language processing tasks are important stepping stones to encourage the growth of research efforts in the field. To answer this call, we introduce CebuaNER, a new baseline model for named entity recognition (NER) in the Cebuano language. Cebuano is the second most-used native language in the Philippines, with over 20 million speakers. To build the model, we collected and annotated over 4,000 news articles, the largest of any work in the language, retrieved from online local Cebuano platforms to train algorithms such as Conditional Random Field and Bidirectional LSTM. Our findings show promising results as a new baseline model, achieving over 70% performance on precision, recall, and F1 across all entity tags, as well as potential efficacy in a crosslingual setup with Tagalog.
Smart Metro: Deep Learning Approaches to Forecasting the MRT Line 3 Ridership
Apr 14, 2023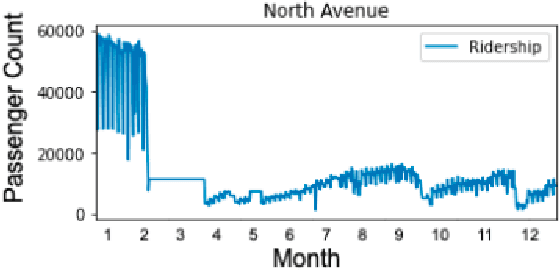
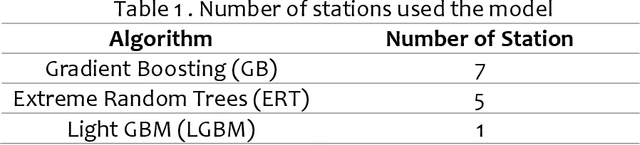
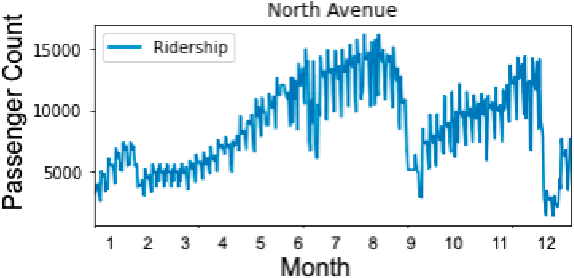
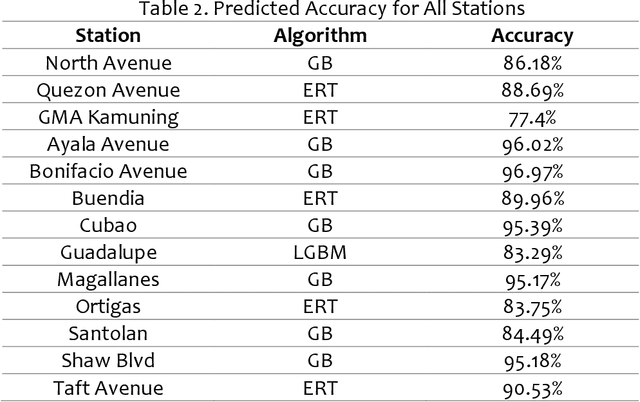
Since its establishment in 1999, the Metro Rail Transit Line 3 (MRT3) has served as a transportation option for numerous passengers in Metro Manila, Philippines. The Philippine government's transportation department records more than a thousand people using the MRT3 daily and forecasting the daily passenger count may be rather challenging. The MRT3's daily ridership fluctuates owing to variables such as holidays, working days, and other unexpected issues. Commuters do not know how many other commuters are on their route on a given day, which may hinder their ability to plan an efficient itinerary. Currently, the DOTr depends on spreadsheets containing historical data, which might be challenging to examine. This study presents a time series prediction of daily traffic to anticipate future attendance at a particular station on specific days.