 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEng4NN: An Accurate Performance Estimation Engine for Efficient Automated Neural Network Architecture Search
Jan 11, 2021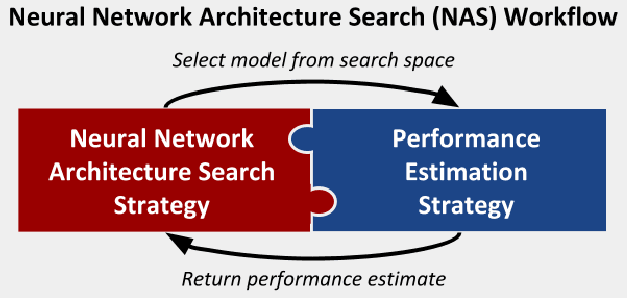
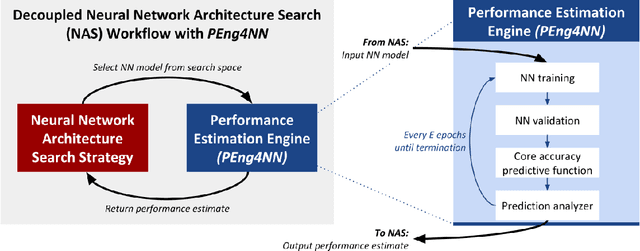
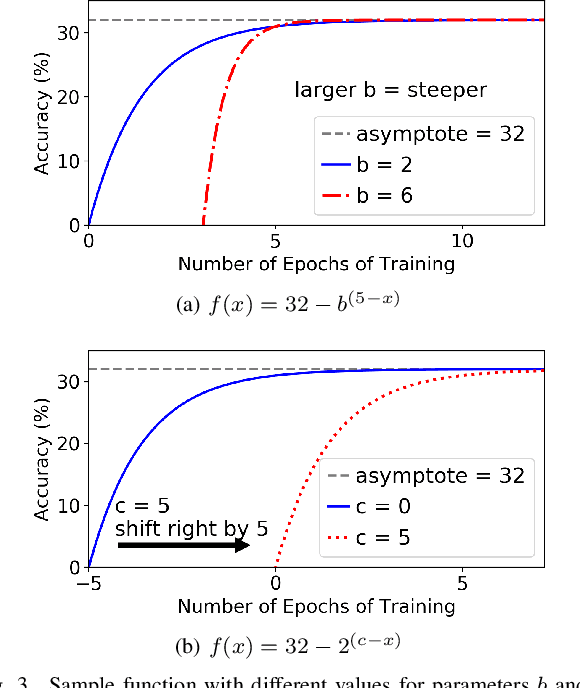
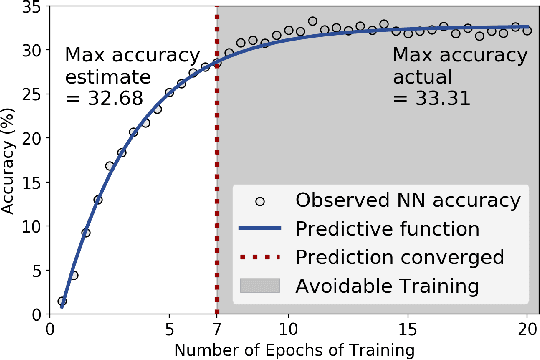
Neural network (NN) models are increasingly used in scientific simulations, AI, and other high performance computing (HPC) fields to extract knowledge from datasets. Each dataset requires tailored NN model architecture, but designing structures by hand is a time-consuming and error-prone process. Neural architecture search (NAS) automates the design of NN architectures. NAS attempts to find well-performing NN models for specialized datsets, where performance is measured by key metrics that capture the NN capabilities (e.g., accuracy of classification of samples in a dataset). Existing NAS methods are resource intensive, especially when searching for highly accurate models for larger and larger datasets. To address this problem, we propose a performance estimation strategy that reduces the resources for training NNs and increases NAS throughput without jeopardizing accuracy. We implement our strategy via an engine called PEng4NN that plugs into existing NAS methods; in doing so, PEng4NN predicts the final accuracy of NNs early in the training process, informs the NAS of NN performance, and thus enables the NAS to terminate training NNs early. We assess our engine on three diverse datasets (i.e., CIFAR-100, Fashion MNIST, and SVHN). By reducing the training epochs needed, our engine achieves substantial throughput gain; on average, our engine saves $61\%$ to $82\%$ of training epochs, increasing throughput by a factor of 2.5 to 5 compared to a state-of-the-art NAS method. We achieve this gain without compromising accuracy, as we demonstrate with two key outcomes. First, across all our tests, between $74\%$ and $97\%$ of the ground truth best models lie in our set of predicted best models. Second, the accuracy distributions of the ground truth best models and our predicted best models are comparable, with the mean accuracy values differing by at most .7 percentage points across all tests.
SOMOSPIE: A modular SOil MOisture SPatial Inference Engine based on data driven decisions
May 20, 2019
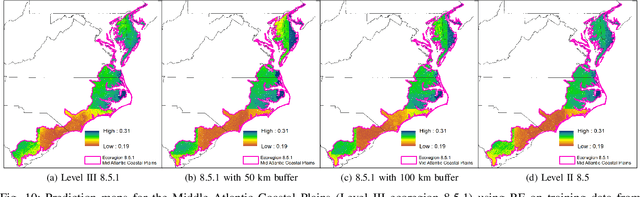


The current availability of soil moisture data over large areas comes from satellite remote sensing technologies (i.e., radar-based systems), but these data have coarse resolution and often exhibit large spatial information gaps. Where data are too coarse or sparse for a given need (e.g., precision agriculture), one can leverage machine-learning techniques coupled with other sources of environmental information (e.g., topography) to generate gap-free information and at a finer spatial resolution (i.e., increased granularity). To this end, we develop a spatial inference engine consisting of modular stages for processing spatial environmental data, generating predictions with machine-learning techniques, and analyzing these predictions. We demonstrate the functionality of this approach and the effects of data processing choices via multiple prediction maps over a United States ecological region with a highly diverse soil moisture profile (i.e., the Middle Atlantic Coastal Plains). The relevance of our work derives from a pressing need to improve the spatial representation of soil moisture for applications in environmental sciences (e.g., ecological niche modeling, carbon monitoring systems, and other Earth system models) and precision agriculture (e.g., optimizing irrigation practices and other land management decisions).