 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning-based patient selection in an emergency department
Jun 08, 2022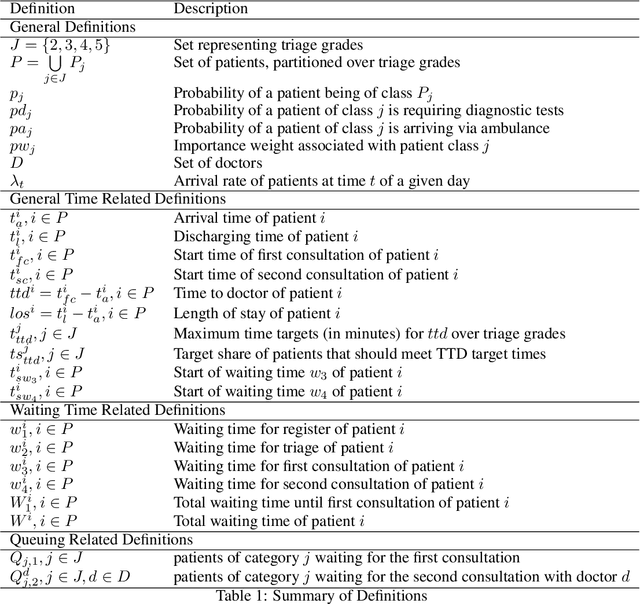
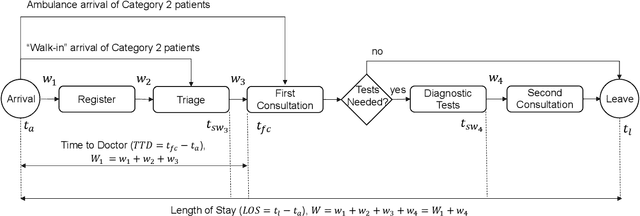
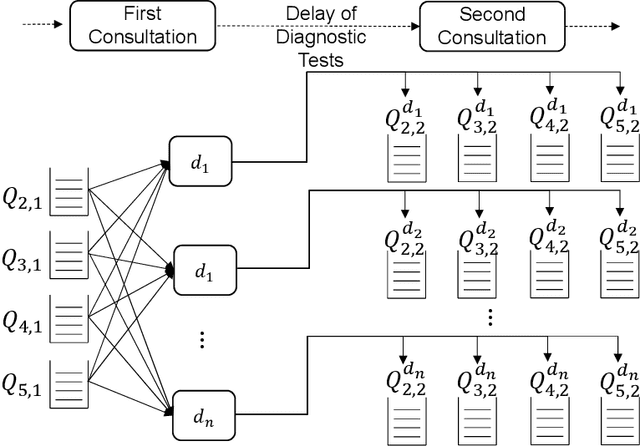
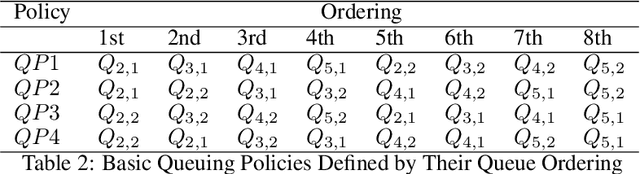
The performance of Emergency Departments (EDs) is of great importance for any health care system, as they serve as the entry point for many patients. However, among other factors, the variability of patient acuity levels and corresponding treatment requirements of patients visiting EDs imposes significant challenges on decision makers. Balancing waiting times of patients to be first seen by a physician with the overall length of stay over all acuity levels is crucial to maintain an acceptable level of operational performance for all patients. To address those requirements when assigning idle resources to patients, several methods have been proposed in the past, including the Accumulated Priority Queuing (APQ) method. The APQ method linearly assigns priority scores to patients with respect to their time in the system and acuity level. Hence, selection decisions are based on a simple system representation that is used as an input for a selection function. This paper investigates the potential of an Machine Learning (ML) based patient selection method. It assumes that for a large set of training data, including a multitude of different system states, (near) optimal assignments can be computed by a (heuristic) optimizer, with respect to a chosen performance metric, and aims to imitate such optimal behavior when applied to new situations. Thereby, it incorporates a comprehensive state representation of the system and a complex non-linear selection function. The motivation for the proposed approach is that high quality selection decisions may depend on a variety of factors describing the current state of the ED, not limited to waiting times, which can be captured and utilized by the ML model. Results show that the proposed method significantly outperforms the APQ method for a majority of evaluated settings
A Methodology to Select Topology Generators for WANET Simulations (Extended Version)
Aug 26, 2019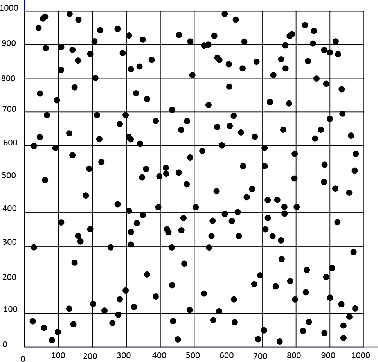


Many academic and industrial research works on WANETs rely on simulations, at least in the first stages, to obtain preliminary results to be subsequently validated in real settings. Topology generators (TG) are commonly used to generate the initial placement of nodes in artificial WANET topologies, where those simulations take place. The significance of these experiments heavily depends on the representativeness of artificial topologies. Indeed, if they were not drawn fairly, obtained results would apply only to a subset of possible configurations, hence they would lack of the appropriate generality required to port them to the real world. Although using many TGs could mitigate this issue by generating topologies in several different ways, that would entail a significant additional effort. Hence, the problem arises of what TGs to choose, among a number of available generators, to maximise the representativeness of generated topologies and reduce the number of TGs to use. In this paper, we address that problem by investigating the presence of bias in the initial placement of nodes in artificial WANET topologies produced by different TGs. We propose a methodology to assess such bias and introduce two metrics to quantify the diversity of the topologies generated by a TG with respect to all the available TGs, which can be used to select what TGs to use. We carry out experiments on three well-known TGs, namely BRITE, NPART and GT-ITM. Obtained results show that using the artificial networks produced by a single TG can introduce bias.