 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Here, Go There: Analyzing Redirection Patterns on the Web
Jul 29, 2025URI redirections are integral to web management, supporting structural changes, SEO optimization, and security. However, their complexities affect usability, SEO performance, and digital preservation. This study analyzed 11 million unique redirecting URIs, following redirections up to 10 hops per URI, to uncover patterns and implications of redirection practices. Our findings revealed that 50% of the URIs terminated successfully, while 50% resulted in errors, including 0.06% exceeding 10 hops. Canonical redirects, such as HTTP to HTTPS transitions, were prevalent, reflecting adherence to SEO best practices. Non-canonical redirects, often involving domain or path changes, highlighted significant web migrations, rebranding, and security risks. Notable patterns included "sink" URIs, where multiple redirects converged, ranging from traffic consolidation by global websites to deliberate "Rickrolling." The study also identified 62,000 custom 404 URIs, almost half being soft 404s, which could compromise SEO and user experience. These findings underscore the critical role of URI redirects in shaping the web while exposing challenges such as outdated URIs, server instability, and improper error handling. This research offers a detailed analysis of URI redirection practices, providing insights into their prevalence, types, and outcomes. By examining a large dataset, we highlight inefficiencies in redirection chains and examine patterns such as the use of "sink" URIs and custom error pages. This information can help webmasters, researchers, and digital archivists improve web usability, optimize resource allocation, and safeguard valuable online content.
GitHub Repository Complexity Leads to Diminished Web Archive Availability
May 21, 2025Software is often developed using versioned controlled software, such as Git, and hosted on centralized Web hosts, such as GitHub and GitLab. These Web hosted software repositories are made available to users in the form of traditional HTML Web pages for each source file and directory, as well as a presentational home page and various descriptive pages. We examined more than 12,000 Web hosted Git repository project home pages, primarily from GitHub, to measure how well their presentational components are preserved in the Internet Archive, as well as the source trees of the collected GitHub repositories to assess the extent to which their source code has been preserved. We found that more than 31% of the archived repository home pages examined exhibited some form of minor page damage and 1.6% exhibited major page damage. We also found that of the source trees analyzed, less than 5% of their source files were archived, on average, with the majority of repositories not having source files saved in the Internet Archive at all. The highest concentration of archived source files available were those linked directly from repositories' home pages at a rate of 14.89% across all available repositories and sharply dropping off at deeper levels of a repository's directory tree.
Categorizing Social Media Screenshots for Identifying Author Misattribution
Oct 09, 2024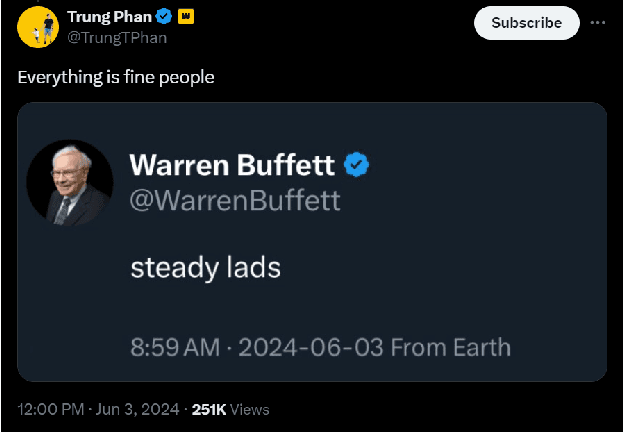

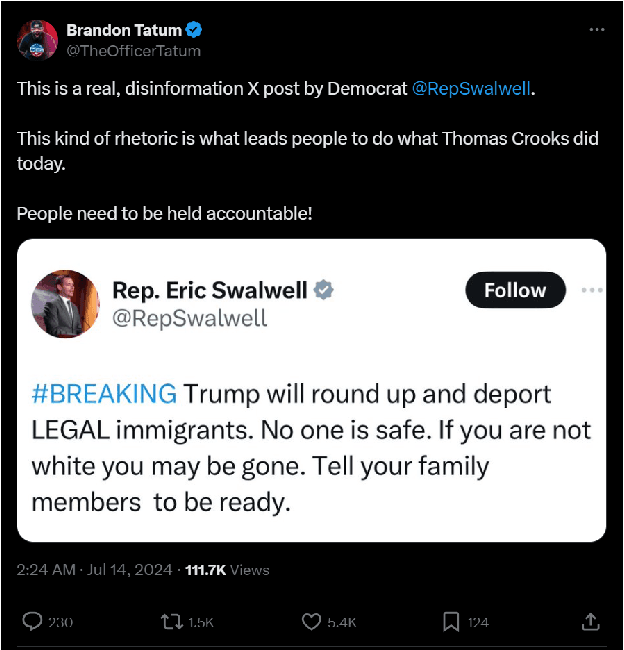

Mis/disinformation is a common and dangerous occurrence on social media. Misattribution is a form of mis/disinformation that deals with a false claim of authorship, which means a user is claiming someone said (posted) something they never did. We discuss the difference between misinformation and disinformation and how screenshots are used to spread author misattribution on social media platforms. It is important to be able to find the original post of a screenshot to determine if the screenshot is being correctly attributed. To do this we have built several tools to aid in automating this search process. The first is a Python script that aims to categorize Twitter posts based on their structure, extract the metadata from a screenshot, and use this data to group all the posts within a screenshot together. We tested this process on 75 Twitter posts containing screenshots collected by hand to determine how well the script extracted metadata and grouped the individual posts, F1 = 0.80. The second is a series of scrapers being used to collect a dataset that can train and test a model to differentiate between various social media platforms. We collected 16,620 screenshots have been collected from Facebook, Instagram, Truth Social, and Twitter. Screenshots were taken by the scrapers of the web version and mobile version of each platform in both light and dark mode.
Extracting Information from Twitter Screenshots
Jun 14, 2023



Screenshots are prevalent on social media as a common approach for information sharing. Users rarely verify before sharing a screenshot whether the post it contains is fake or real. Information sharing through fake screenshots can be highly responsible for misinformation and disinformation spread on social media. Our ultimate goal is to develop a tool that could take a screenshot of a tweet and provide a probability that the tweet is real, using resources found on the live web and in web archives. This paper provides methods for extracting the tweet text, timestamp, and Twitter handle from a screenshot of a tweet.
Making Changes in Webpages Discoverable: A Change-Text Search Interface for Web Archives
Apr 30, 2023Webpages change over time, and web archives hold copies of historical versions of webpages. Users of web archives, such as journalists, want to find and view changes on webpages over time. However, the current search interfaces for web archives do not support this task. For the web archives that include a full-text search feature, multiple versions of the same webpage that match the search query are shown individually without enumerating changes, or are grouped together in a way that hides changes. We present a change text search engine that allows users to find changes in webpages. We describe the implementation of the search engine backend and frontend, including a tool that allows users to view the changes between two webpage versions in context as an animation. We evaluate the search engine with U.S. federal environmental webpages that changed between 2016 and 2020. The change text search results page can clearly show when terms and phrases were added or removed from webpages. The inverted index can also be queried to identify salient and frequently deleted terms in a corpus.
Did They Really Tweet That? Querying Fact-Checking Sites and Politwoops to Determine Tweet Misattribution
Nov 17, 2022



Screenshots of social media posts have become common place on social media sites. While screenshots definitely serve a purpose, their ubiquity enables the spread of fabricated screenshots of posts that were never actually made, thereby proliferating misattribution disinformation. With the motivation of detecting this type of disinformation, we researched developing methods of querying the Web for evidence of a tweet's existence. We developed software that automatically makes search queries utilizing the body of alleged tweets to a variety of services (Google, Snopes built-in search, and Reuters built-in search) in an effort to find fact-check articles and other evidence of supposedly made tweets. We also developed tools to automatically search the site Politwoops for a particular tweet that may have been made and deleted by an elected official. In addition, we developed software to scrape fact-check articles from the sites Reuters.com and Snopes.com in order to derive a ``truth rating" from any given article from these sites. For evaluation, we began the construction of a ground truth dataset of tweets with known evidence (currently only Snopes fact-check articles) on the live web, and we gathered MRR and P@1 values based on queries made using only the bodies of those tweets. These queries showed that the Snopes built-in search was effective at finding appropriate articles about half of the time with MRR=0.5500 and P@1=0.5333, while Google when used with the site:snopes.com operator was generally effective at finding the articles in question, with MRR=0.8667 and P@1=0.8667.
Profiling Web Archival Voids for Memento Routing
Aug 06, 2021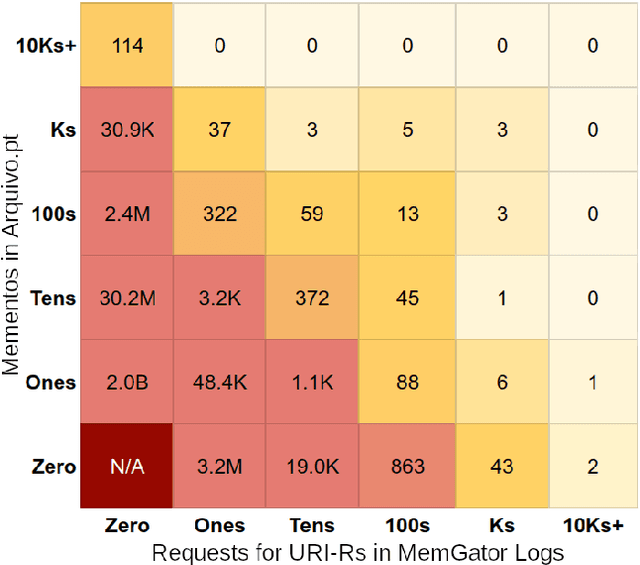
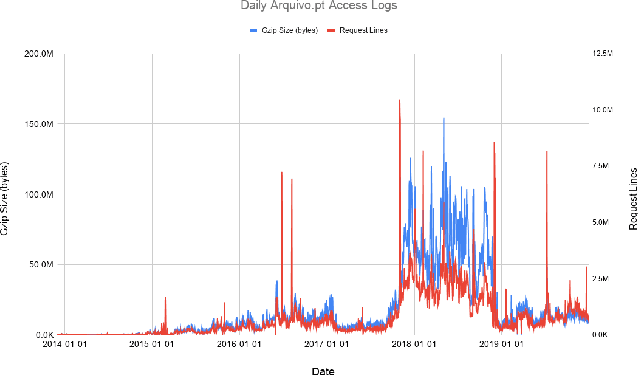
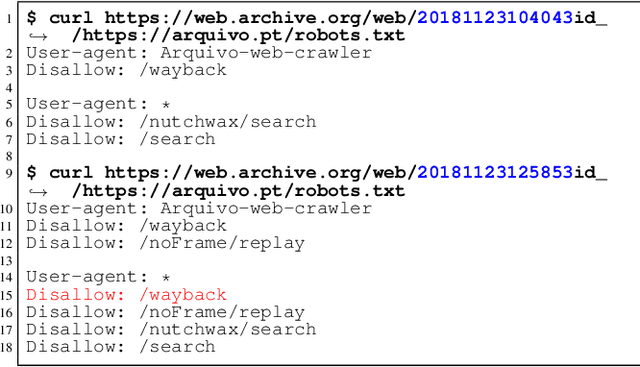
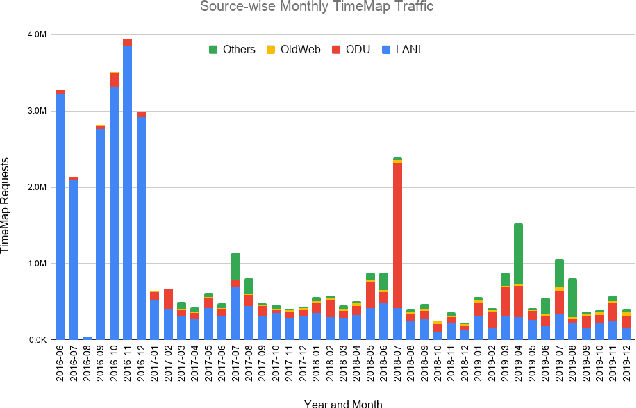
Prior work on web archive profiling were focused on Archival Holdings to describe what is present in an archive. This work defines and explores Archival Voids to establish a means to represent portions of URI spaces that are not present in a web archive. Archival Holdings and Archival Voids profiles can work independently or as complements to each other to maximize the Accuracy of Memento Aggregators. We discuss various sources of truth that can be used to create Archival Voids profiles. We use access logs from Arquivo.pt to create various Archival Voids profiles and analyze them against our MemGator access logs for evaluation. We find that we could have avoided more than 8% of additional False Positives on top of the 60% Accuracy we got from profiling Archival Holdings in our prior work, if Arquivo.pt were to provide an Archival Voids profile based on URIs that were requested hundreds of times and never returned any success responses.
365 Dots in 2019: Quantifying Attention of News Sources
Mar 22, 2020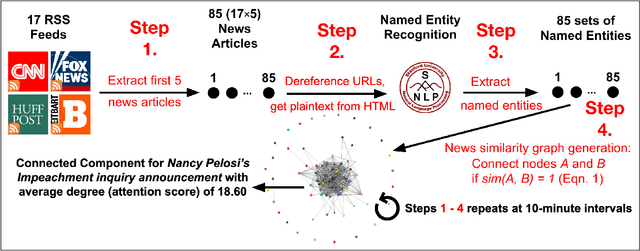

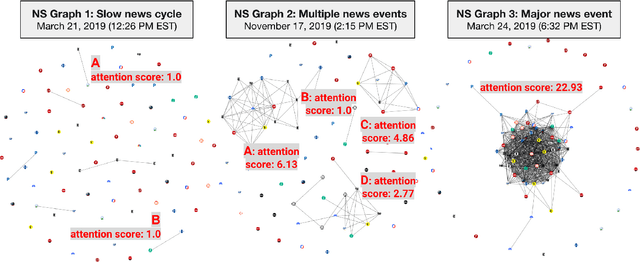
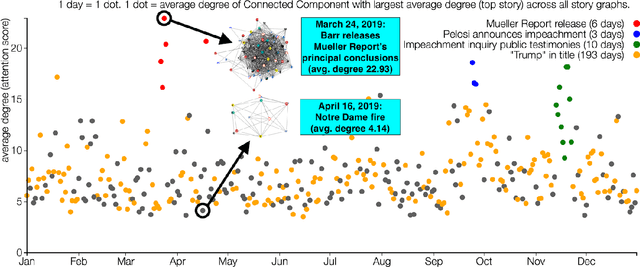
We investigate the overlap of topics of online news articles from a variety of sources. To do this, we provide a platform for studying the news by measuring this overlap and scoring news stories according to the degree of attention in near-real time. This can enable multiple studies, including identifying topics that receive the most attention from news organizations and identifying slow news days versus major news days. Our application, StoryGraph, periodically (10-minute intervals) extracts the first five news articles from the RSS feeds of 17 US news media organizations across the partisanship spectrum (left, center, and right). From these articles, StoryGraph extracts named entities (PEOPLE, LOCATIONS, ORGANIZATIONS, etc.) and then represents each news article with its set of extracted named entities. Finally, StoryGraph generates a news similarity graph where the nodes represent news articles, and an edge between a pair of nodes represents a high degree of similarity between the nodes (similar news stories). Each news story within the news similarity graph is assigned an attention score which quantifies the amount of attention the topics in the news story receive collectively from the news media organizations. The StoryGraph service has been running since August 2017, and using this method, we determined that the top news story of 2018 was the "Kavanaugh hearings" with attention score of 25.85 on September 27, 2018. Similarly, the top news story for 2019 so far (2019-12-12) is "AG William Barr's release of his principal conclusions of the Mueller Report," with an attention score of 22.93 on March 24, 2019.