 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Excavating AI" Re-excavated: Debunking a Fallacious Account of the JAFFE Dataset
Jul 28, 2021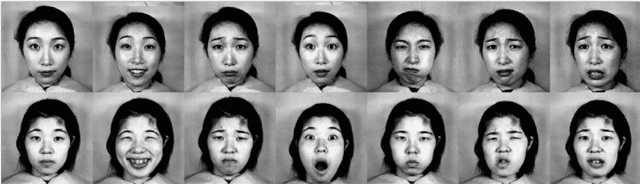
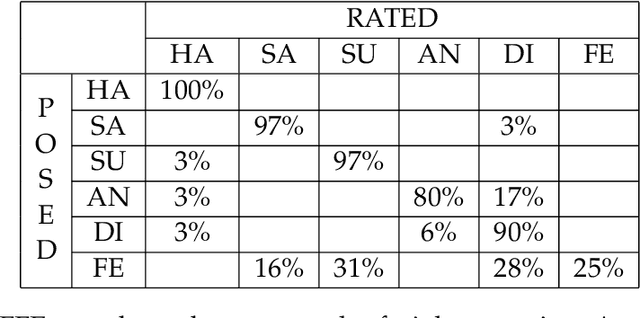
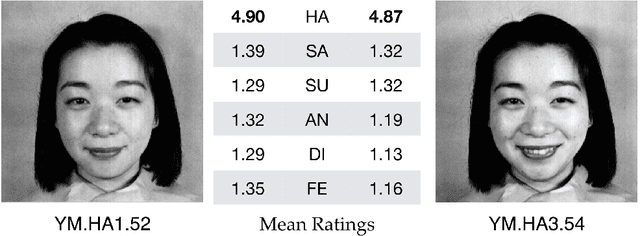
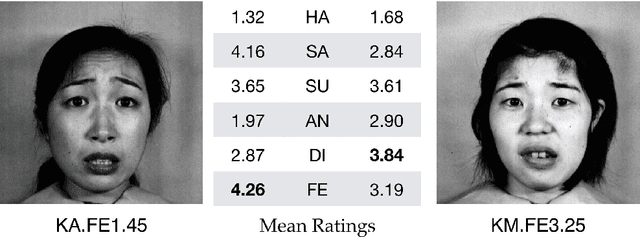
Twenty-five years ago, my colleagues Miyuki Kamachi and Jiro Gyoba and I designed and photographed JAFFE, a set of facial expression images intended for use in a study of face perception. In 2019, without seeking permission or informing us, Kate Crawford and Trevor Paglen exhibited JAFFE in two widely publicized art shows. In addition, they published a nonfactual account of the images in the essay "Excavating AI: The Politics of Images in Machine Learning Training Sets." The present article recounts the creation of the JAFFE dataset and unravels each of Crawford and Paglen's fallacious statements. I also discuss JAFFE more broadly in connection with research on facial expression, affective computing, and human-computer interaction.
A Novel Face-tracking Mouth Controller and its Application to Interacting with Bioacoustic Models
Oct 07, 2020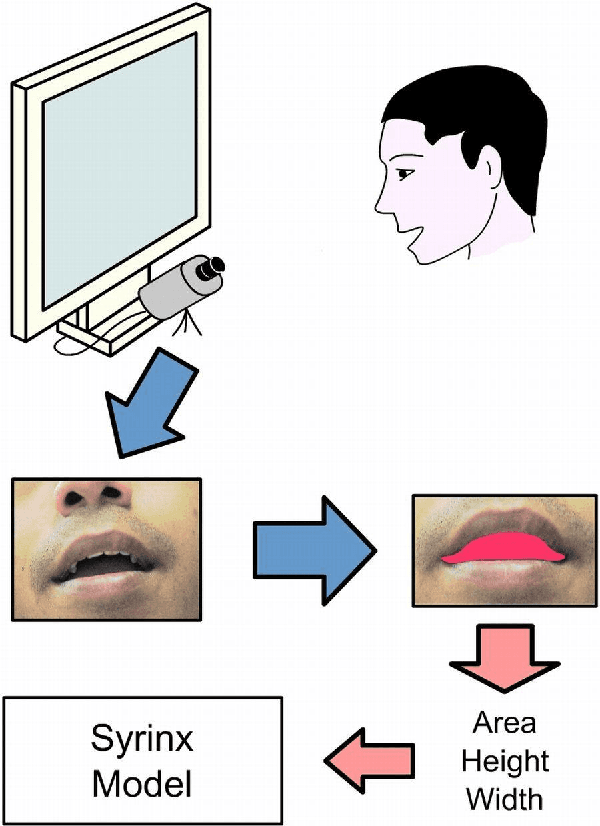
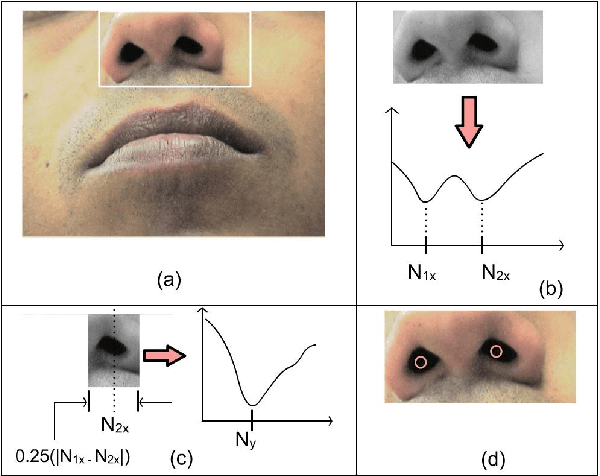
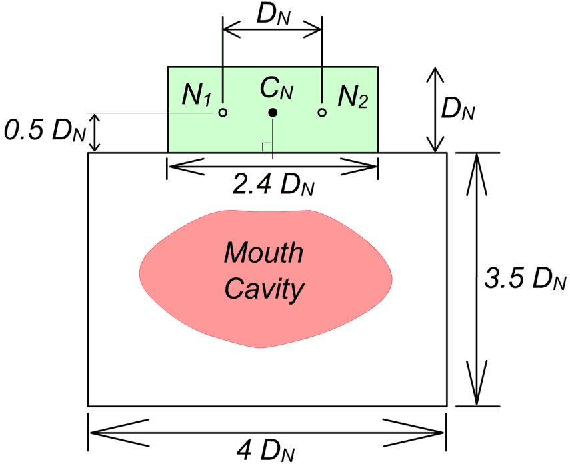
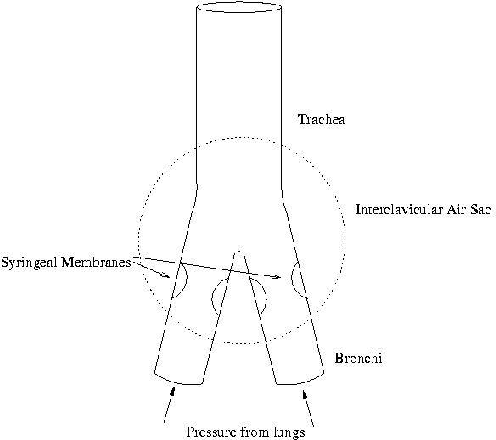
We describe a simple, computationally light, real-time system for tracking the lower face and extracting information about the shape of the open mouth from a video sequence. The system allows unencumbered control of audio synthesis modules by the action of the mouth. We report work in progress to use the mouth controller to interact with a physical model of sound production by the avian syrinx.
Sonification of Facial Actions for Musical Expression
Oct 07, 2020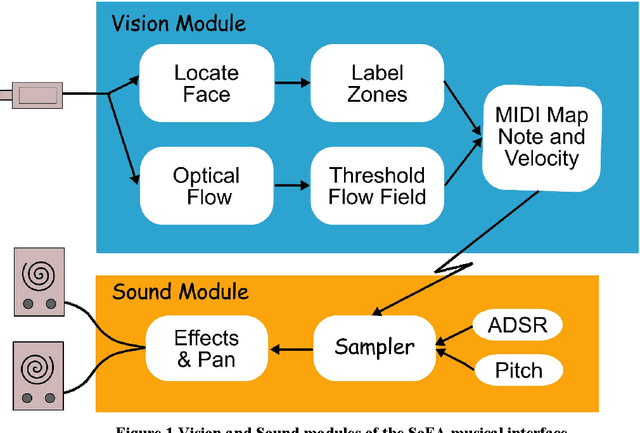


The central role of the face in social interaction and non-verbal communication suggests we explore facial action as a means of musical expression. This paper presents the design, implementation, and preliminary studies of a novel system utilizing face detection and optic flow algorithms to associate facial movements with sound synthesis in a topographically specific fashion. We report on our experience with various gesture-to-sound mappings and applications, and describe our preliminary experiments at musical performance using the system.
Designing, Playing, and Performing with a Vision-based Mouth Interface
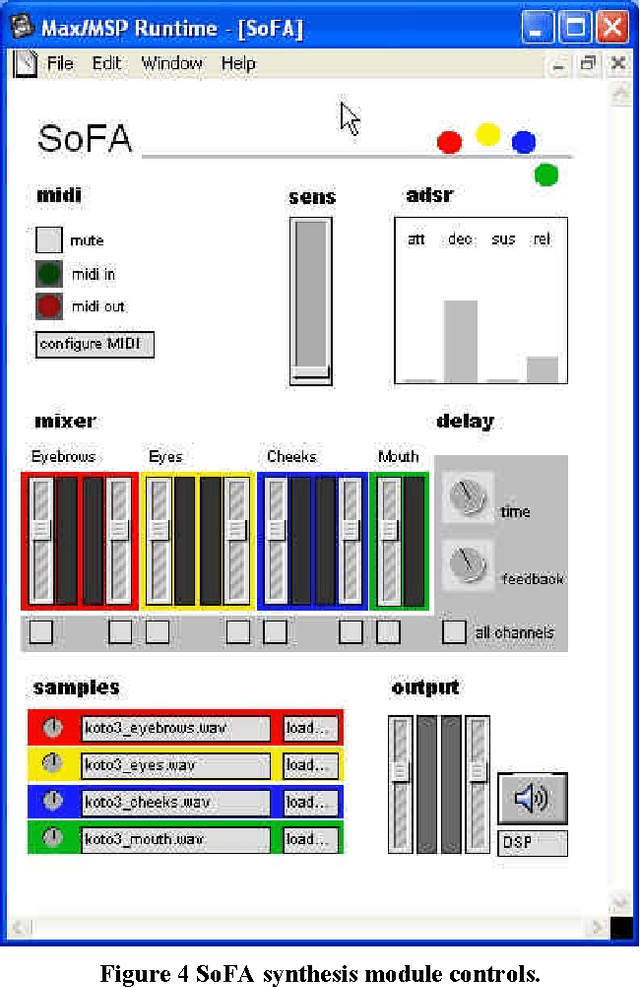
Oct 07, 2020


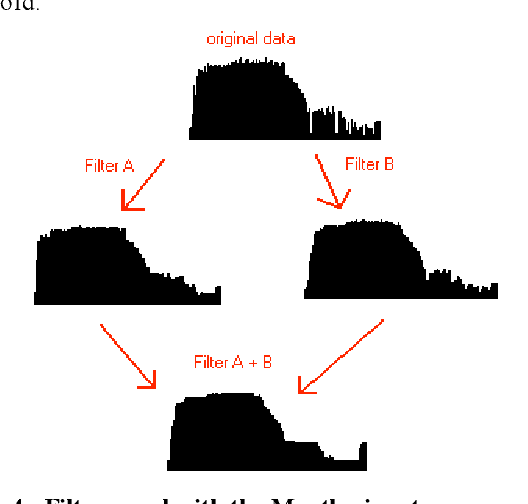
The role of the face and mouth in speech production as well asnon-verbal communication suggests the use of facial action tocontrol musical sound. Here we document work on theMouthesizer, a system which uses a headworn miniaturecamera and computer vision algorithm to extract shapeparameters from the mouth opening and output these as MIDIcontrol changes. We report our experience with variousgesture-to-sound mappings and musical applications, anddescribe a live performance which used the Mouthesizerinterface.
Facial gesture interfaces for expression and communication
Oct 04, 2020
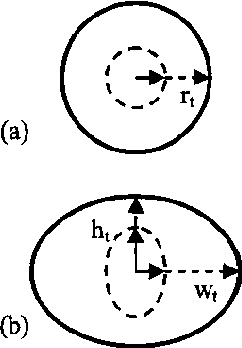
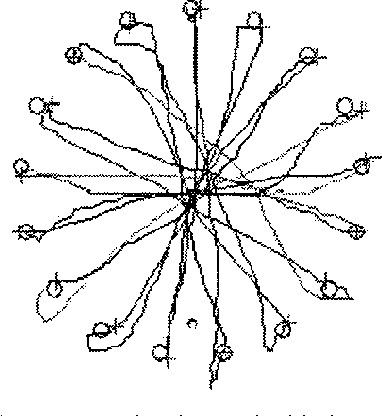

Considerable effort has been devoted to the automatic extraction of information about action of the face from image sequences. Within the context of human-computer interaction (HCI) we may distinguish systems that allow expression from those which aim at recognition. Most of the work in facial action processing has been directed at automatically recognizing affect from facial actions. By contrast, facial gesture interfaces, which respond to deliberate facial actions, have received comparatively little attention. This paper reviews several projects on vision-based interfaces that rely on facial action for intentional HCI. Applications to several domains are introduced, including text entry, artistic and musical expression and assistive technology for motor-impaired users.
* 6 pages, 8 figures
Coding Facial Expressions with Gabor Wavelets (IVC Special Issue)
Sep 13, 2020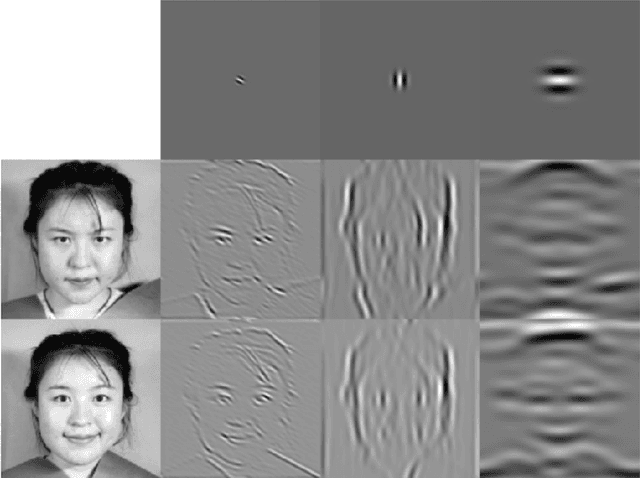
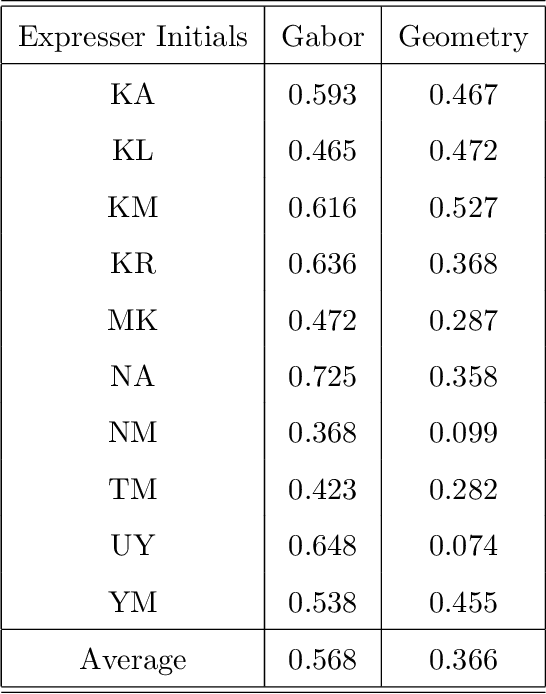

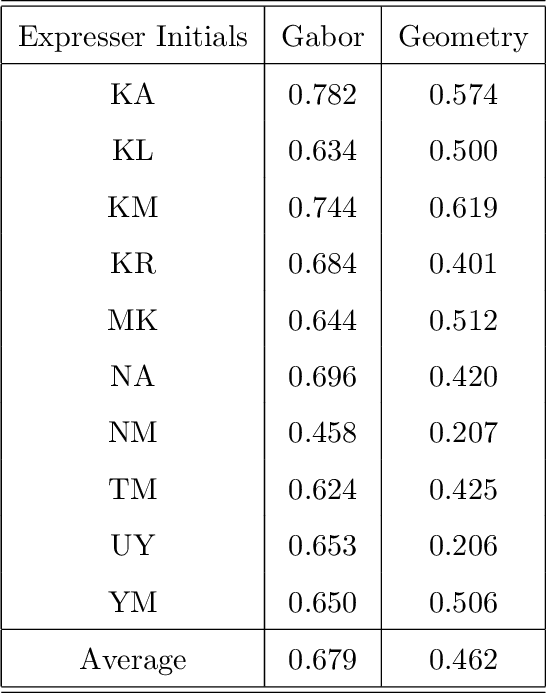
We present a method for extracting information about facial expressions from digital images. The method codes facial expression images using a multi-orientation, multi-resolution set of Gabor filters that are topographically ordered and approximately aligned with the face. A similarity space derived from this code is compared with one derived from semantic ratings of the images by human observers. Interestingly the low-dimensional structure of the image-derived similarity space shares organizational features with the circumplex model of affect, suggesting a bridge between categorical and dimensional representations of facial expression. Our results also indicate that it would be possible to construct a facial expression classifier based on a topographically-linked multi-orientation, multi-resolution Gabor coding of the facial images at the input stage. The significant degree of psychological plausibility exhibited by the proposed code may also be useful in the design of human-computer interfaces.
Excavating "Excavating AI": The Elephant in the Gallery
Sep 04, 2020


Contains critical commentary on the exhibitions "Training Humans" and "Making Faces" by Kate Crawford and Trevor Paglen, and on the accompanying essay "Excavating AI: The politics of images in machine learning training sets."