 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time 3D Shape of Micro-Details
Feb 16, 2018
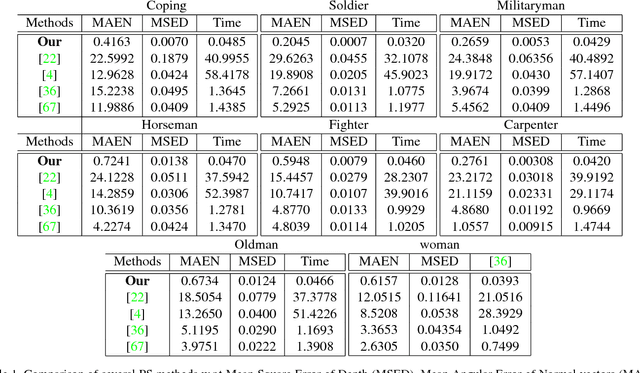


Motivated by the growing demand for interactive environments, we propose an accurate real-time 3D shape reconstruction technique. To provide a reliable 3D reconstruction which is still a challenging task when dealing with real-world applications, we integrate several components including (i) Photometric Stereo (PS), (ii) perspective Cook-Torrance reflectance model that enables PS to deal with a broad range of possible real-world object reflections, (iii) realistic lightening situation, (iv) a Recurrent Optimization Network (RON) and finally (v) heuristic Dijkstra Gaussian Mean Curvature (DGMC) initialization approach. We demonstrate the potential benefits of our hybrid model by providing 3D shape with highly-detailed information from micro-prints for the first time. All real-world images are taken by a mobile phone camera under a simple setup as a consumer-level equipment. In addition, complementary synthetic experiments confirm the beneficial properties of our novel method and its superiority over the state-of-the-art approaches.
Deep Interactive Region Segmentation and Captioning
Jul 26, 2017


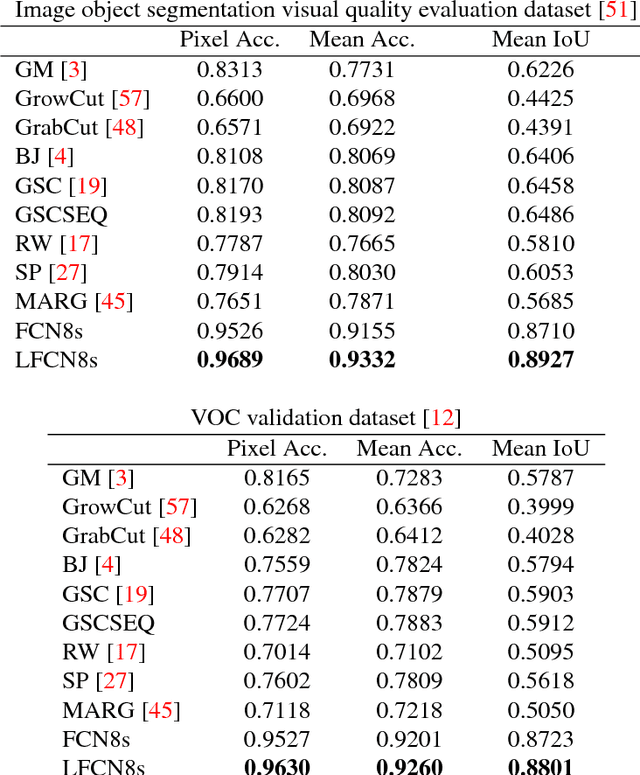
With recent innovations in dense image captioning, it is now possible to describe every object of the scene with a caption while objects are determined by bounding boxes. However, interpretation of such an output is not trivial due to the existence of many overlapping bounding boxes. Furthermore, in current captioning frameworks, the user is not able to involve personal preferences to exclude out of interest areas. In this paper, we propose a novel hybrid deep learning architecture for interactive region segmentation and captioning where the user is able to specify an arbitrary region of the image that should be processed. To this end, a dedicated Fully Convolutional Network (FCN) named Lyncean FCN (LFCN) is trained using our special training data to isolate the User Intention Region (UIR) as the output of an efficient segmentation. In parallel, a dense image captioning model is utilized to provide a wide variety of captions for that region. Then, the UIR will be explained with the caption of the best match bounding box. To the best of our knowledge, this is the first work that provides such a comprehensive output. Our experiments show the superiority of the proposed approach over state-of-the-art interactive segmentation methods on several well-known datasets. In addition, replacement of the bounding boxes with the result of the interactive segmentation leads to a better understanding of the dense image captioning output as well as accuracy enhancement for the object detection in terms of Intersection over Union (IoU).