 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Separation of Small Classical Ensembles: Challenges and Opportunities
May 23, 2025Musical (MSS) source separation of western popular music using non-causal deep learning can be very effective. In contrast, MSS for classical music is an unsolved problem. Classical ensembles are harder to separate than popular music because of issues such as the inherent greater variation in the music; the sparsity of recordings with ground truth for supervised training; and greater ambiguity between instruments. The Cadenza project has been exploring MSS for classical music. This is being done so music can be remixed to improve listening experiences for people with hearing loss. To enable the work, a new database of synthesized woodwind ensembles was created to overcome instrumental imbalances in the EnsembleSet. For the MSS, a set of ConvTasNet models was used with each model being trained to extract a string or woodwind instrument. ConvTasNet was chosen because it enabled both causal and non-causal approaches to be tested. Non-causal approaches have dominated MSS work and are useful for recorded music, but for live music or processing on hearing aids, causal signal processing is needed. The MSS performance was evaluated on the two small datasets (Bach10 and URMP) of real instrument recordings where the ground-truth is available. The performances of the causal and non-causal systems were similar. Comparing the average Signal-to-Distortion (SDR) of the synthesized validation set (6.2 dB causal; 6.9 non-causal), to the real recorded evaluation set (0.3 dB causal, 0.4 dB non-causal), shows that mismatch between synthesized and recorded data is a problem. Future work needs to either gather more real recordings that can be used for training, or to improve the realism and diversity of the synthesized recordings to reduce the mismatch...
The first Cadenza challenges: using machine learning competitions to improve music for listeners with a hearing loss
Sep 08, 2024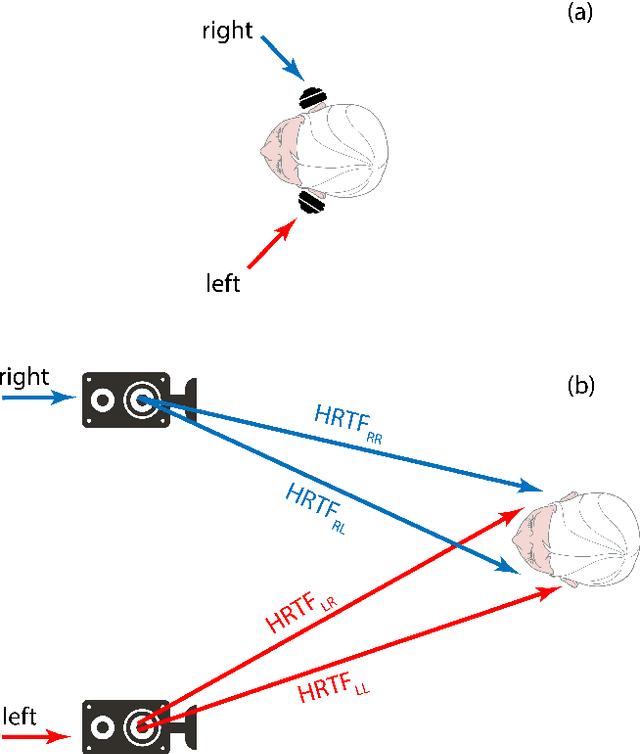

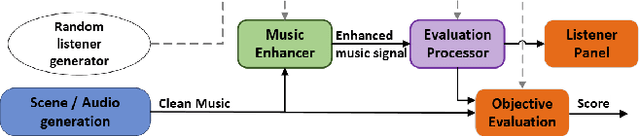

It is well established that listening to music is an issue for those with hearing loss, and hearing aids are not a universal solution. How can machine learning be used to address this? This paper details the first application of the open challenge methodology to use machine learning to improve audio quality of music for those with hearing loss. The first challenge was a stand-alone competition (CAD1) and had 9 entrants. The second was an 2024 ICASSP grand challenge (ICASSP24) and attracted 17 entrants. The challenge tasks concerned demixing and remixing pop/rock music to allow a personalised rebalancing of the instruments in the mix, along with amplification to correct for raised hearing thresholds. The software baselines provided for entrants to build upon used two state-of-the-art demix algorithms: Hybrid Demucs and Open-Unmix. Evaluation of systems was done using the objective metric HAAQI, the Hearing-Aid Audio Quality Index. No entrants improved on the best baseline in CAD1 because there was insufficient room for improvement. Consequently, for ICASSP24 the scenario was made more difficult by using loudspeaker reproduction and specified gains to be applied before remixing. This also made the scenario more useful for listening through hearing aids. 9 entrants scored better than the the best ICASSP24 baseline. Most entrants used a refined version of Hybrid Demucs and NAL-R amplification. The highest scoring system combined the outputs of several demixing algorithms in an ensemble approach. These challenges are now open benchmarks for future research with the software and data being freely available.
Overview Of The 2023 Icassp Sp Clarity Challenge: Speech Enhancement For Hearing Aids
Nov 24, 2023
This paper reports on the design and outcomes of the ICASSP SP Clarity Challenge: Speech Enhancement for Hearing Aids. The scenario was a listener attending to a target speaker in a noisy, domestic environment. There were multiple interferers and head rotation by the listener. The challenge extended the second Clarity Enhancement Challenge (CEC2) by fixing the amplification stage of the hearing aid; evaluating with a combined metric for speech intelligibility and quality; and providing two evaluation sets, one based on simulation and the other on real-room measurements. Five teams improved on the baseline system for the simulated evaluation set, but the performance on the measured evaluation set was much poorer. Investigations are on-going to determine the exact cause of the mismatch between the simulated and measured data sets. The presence of transducer noise in the measurements, lower order Ambisonics harming the ability for systems to exploit binaural cues and the differences between real and simulated room impulse responses are suggested causes
The First Cadenza Signal Processing Challenge: Improving Music for Those With a Hearing Loss
Oct 09, 2023The Cadenza project aims to improve the audio quality of music for those who have a hearing loss. This is being done through a series of signal processing challenges, to foster better and more inclusive technologies. In the first round, two common listening scenarios are considered: listening to music over headphones, and with a hearing aid in a car. The first scenario is cast as a demixing-remixing problem, where the music is decomposed into vocals, bass, drums and other components. These can then be intelligently remixed in a personalized way, to increase the audio quality for a person who has a hearing loss. In the second scenario, music is coming from car loudspeakers, and the music has to be enhanced to overcome the masking effect of the car noise. This is done by taking into account the music, the hearing ability of the listener, the hearing aid and the speed of the car. The audio quality of the submissions will be evaluated using the Hearing Aid Audio Quality Index (HAAQI) for objective assessment and by a panel of people with hearing loss for subjective evaluation.
The Cadenza ICASSP 2024 Grand Challenge
Oct 05, 2023


The Cadenza project aims to enhance the audio quality of music for individuals with hearing loss. As part of this, the project is organizing the ICASSP SP Cadenza Challenge: Music Demixing/Remixing for Hearing Aids. The challenge can be tackled by decomposing the music at the hearing aid microphones into vocals, bass, drums, and other components. These can then be intelligently remixed in a personalized manner to improve audio quality. Alternatively, an end-to-end approach could be used. Processes need to consider the music itself, the gain applied to each component, and the listener's hearing loss. The submitted entries will be evaluated using the intrusive objective metric, the Hearing Aid Audio Quality Index (HAAQI). This paper outlines the challenge.