 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation is all you need. Prompting Generative Large Language Models for Annotation Tasks in the Social Sciences. A Primer using Open Models
Dec 30, 2023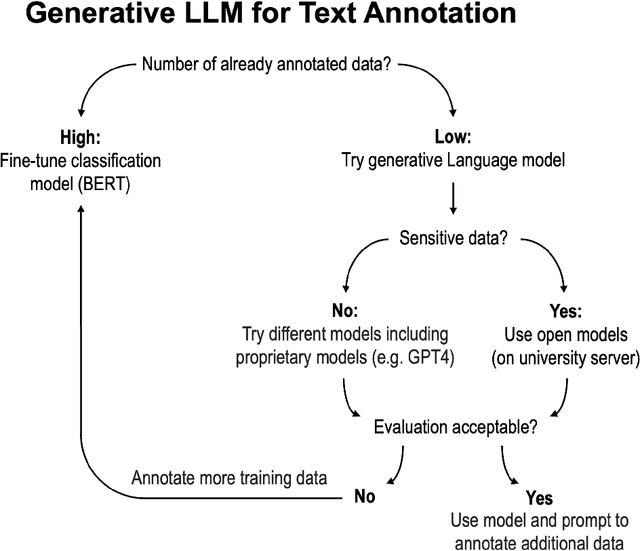


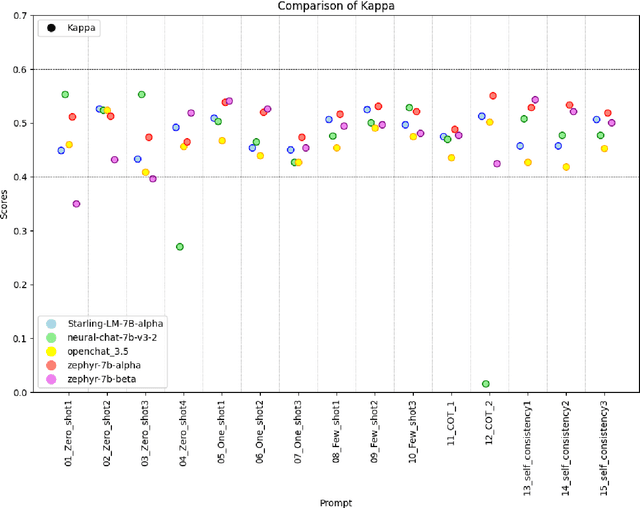
This paper explores the use of open generative Large Language Models (LLMs) for annotation tasks in the social sciences. The study highlights the challenges associated with proprietary models, such as limited reproducibility and privacy concerns, and advocates for the adoption of open (source) models that can be operated on independent devices. Two examples of annotation tasks, sentiment analysis in tweets and identification of leisure activities in childhood aspirational essays are provided. The study evaluates the performance of different prompting strategies and models (neural-chat-7b-v3-2, Starling-LM-7B-alpha, openchat_3.5, zephyr-7b-alpha and zephyr-7b-beta). The results indicate the need for careful validation and tailored prompt engineering. The study highlights the advantages of open models for data privacy and reproducibility.