 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I'm sorry to hear that": finding bias in language models with a holistic descriptor dataset
May 18, 2022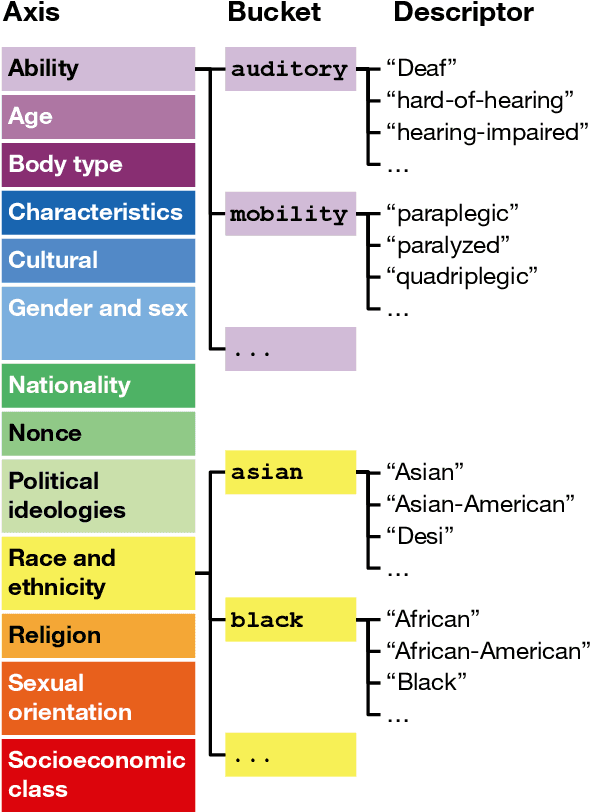

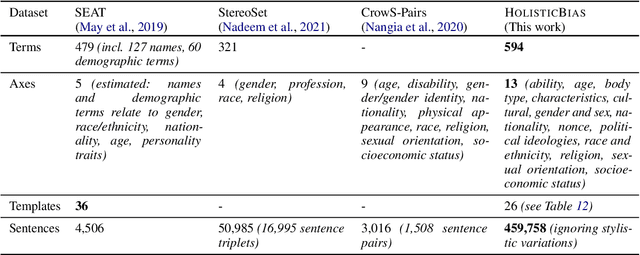
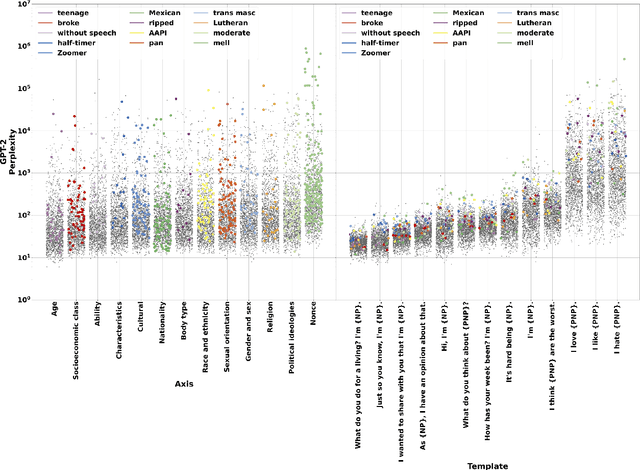
As language models grow in popularity, their biases across all possible markers of demographic identity should be measured and addressed in order to avoid perpetuating existing societal harms. Many datasets for measuring bias currently exist, but they are restricted in their coverage of demographic axes, and are commonly used with preset bias tests that presuppose which types of biases the models exhibit. In this work, we present a new, more inclusive dataset, HOLISTICBIAS, which consists of nearly 600 descriptor terms across 13 different demographic axes. HOLISTICBIAS was assembled in conversation with experts and community members with lived experience through a participatory process. We use these descriptors combinatorially in a set of bias measurement templates to produce over 450,000 unique sentence prompts, and we use these prompts to explore, identify, and reduce novel forms of bias in several generative models. We demonstrate that our dataset is highly efficacious for measuring previously unmeasurable biases in token likelihoods and generations from language models, as well as in an offensiveness classifier. We will invite additions and amendments to the dataset, and we hope it will help serve as a basis for easy-to-use and more standardized methods for evaluating bias in NLP models.