 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyberbullying or just Sarcasm? Unmasking Coordinated Networks on Reddit
Oct 26, 2024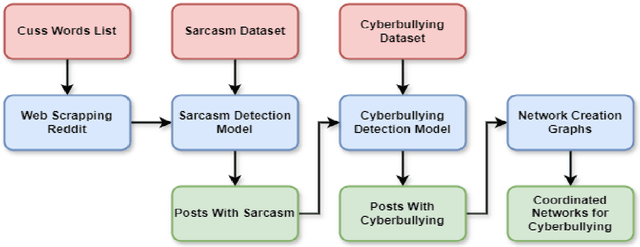


With the rapid growth of social media usage, a common trend has emerged where users often make sarcastic comments on posts. While sarcasm can sometimes be harmless, it can blur the line with cyberbullying, especially when used in negative or harmful contexts. This growing issue has been exacerbated by the anonymity and vast reach of the internet, making cyberbullying a significant concern on platforms like Reddit. Our research focuses on distinguishing cyberbullying from sarcasm, particularly where online language nuances make it difficult to discern harmful intent. This study proposes a framework using natural language processing (NLP) and machine learning to differentiate between the two, addressing the limitations of traditional sentiment analysis in detecting nuanced behaviors. By analyzing a custom dataset scraped from Reddit, we achieved a 95.15% accuracy in distinguishing harmful content from sarcasm. Our findings also reveal that teenagers and minority groups are particularly vulnerable to cyberbullying. Additionally, our research uncovers coordinated graphs of groups involved in cyberbullying, identifying common patterns in their behavior. This research contributes to improving detection capabilities for safer online communities.
A Multimodal Framework for Deepfake Detection
Oct 04, 2024



The rapid advancement of deepfake technology poses a significant threat to digital media integrity. Deepfakes, synthetic media created using AI, can convincingly alter videos and audio to misrepresent reality. This creates risks of misinformation, fraud, and severe implications for personal privacy and security. Our research addresses the critical issue of deepfakes through an innovative multimodal approach, targeting both visual and auditory elements. This comprehensive strategy recognizes that human perception integrates multiple sensory inputs, particularly visual and auditory information, to form a complete understanding of media content. For visual analysis, a model that employs advanced feature extraction techniques was developed, extracting nine distinct facial characteristics and then applying various machine learning and deep learning models. For auditory analysis, our model leverages mel-spectrogram analysis for feature extraction and then applies various machine learning and deep learningmodels. To achieve a combined analysis, real and deepfake audio in the original dataset were swapped for testing purposes and ensured balanced samples. Using our proposed models for video and audio classification i.e. Artificial Neural Network and VGG19, the overall sample is classified as deepfake if either component is identified as such. Our multimodal framework combines visual and auditory analyses, yielding an accuracy of 94%.
* 22 pages, 14 figures, Accepted in Journal of Electrical Systems