 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the Human Visual System: Comparative Insights from Response-Optimized and Task-Optimized Vision Models, Language Models, and different Readout Mechanisms
Oct 17, 2024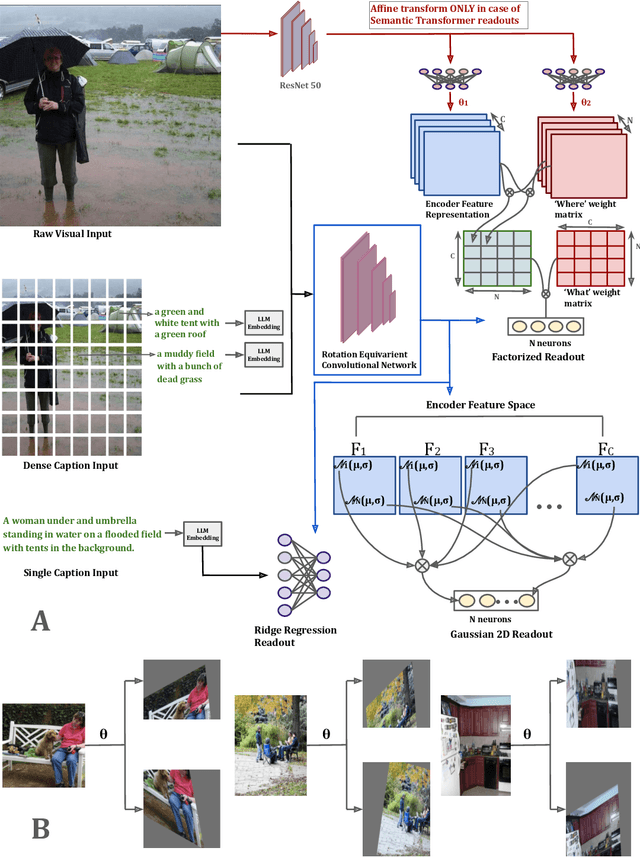



Over the past decade, predictive modeling of neural responses in the primate visual system has advanced significantly, largely driven by various DNN approaches. These include models optimized directly for visual recognition, cross-modal alignment through contrastive objectives, neural response prediction from scratch, and large language model embeddings.Likewise, different readout mechanisms, ranging from fully linear to spatial-feature factorized methods have been explored for mapping network activations to neural responses. Despite the diversity of these approaches, it remains unclear which method performs best across different visual regions. In this study, we systematically compare these approaches for modeling the human visual system and investigate alternative strategies to improve response predictions. Our findings reveal that for early to mid-level visual areas, response-optimized models with visual inputs offer superior prediction accuracy, while for higher visual regions, embeddings from LLMs based on detailed contextual descriptions of images and task-optimized models pretrained on large vision datasets provide the best fit. Through comparative analysis of these modeling approaches, we identified three distinct regions in the visual cortex: one sensitive primarily to perceptual features of the input that are not captured by linguistic descriptions, another attuned to fine-grained visual details representing semantic information, and a third responsive to abstract, global meanings aligned with linguistic content. We also highlight the critical role of readout mechanisms, proposing a novel scheme that modulates receptive fields and feature maps based on semantic content, resulting in an accuracy boost of 3-23% over existing SOTAs for all models and brain regions. Together, these findings offer key insights into building more precise models of the visual system.