 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural disambiguation of lemma and part of speech in morphologically rich languages
Jul 12, 2020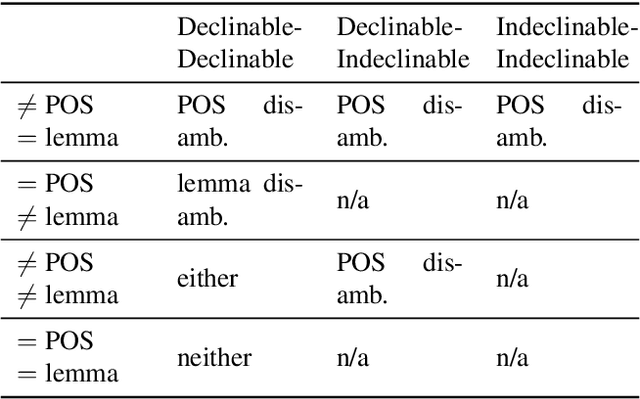

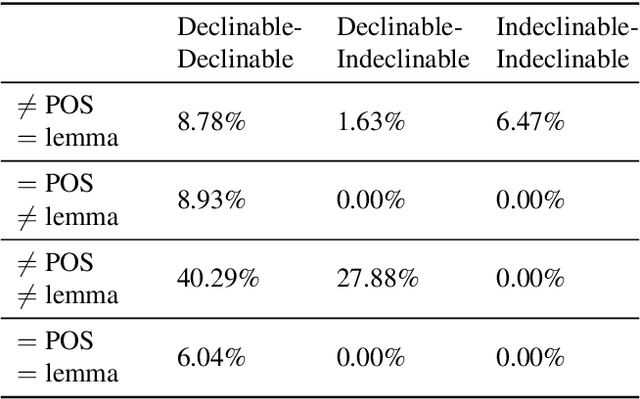
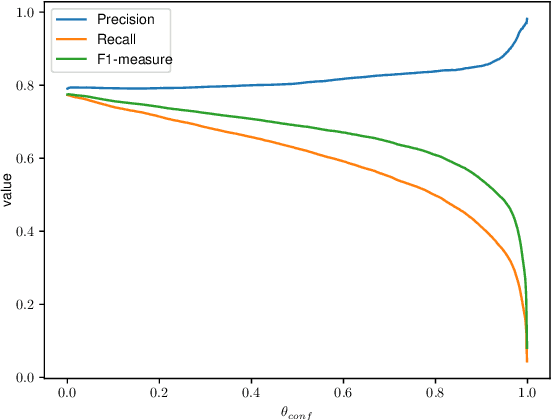
We consider the problem of disambiguating the lemma and part of speech of ambiguous words in morphologically rich languages. We propose a method for disambiguating ambiguous words in context, using a large un-annotated corpus of text, and a morphological analyser -- with no manual disambiguation or data annotation. We assume that the morphological analyser produces multiple analyses for ambiguous words. The idea is to train recurrent neural networks on the output that the morphological analyser produces for unambiguous words. We present performance on POS and lemma disambiguation that reaches or surpasses the state of the art -- including supervised models -- using no manually annotated data. We evaluate the method on several morphologically rich languages.
* This paper contains corrigenda to a previously published paper (Hoya Quecedo et al., 2020). It corrects a mistake in the original evaluation setup, and the results reported in Section 6., in Tables 5, 6, and 7