 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSome Experimental Issues in Financial Fraud Detection: An Investigation
Jan 06, 2016

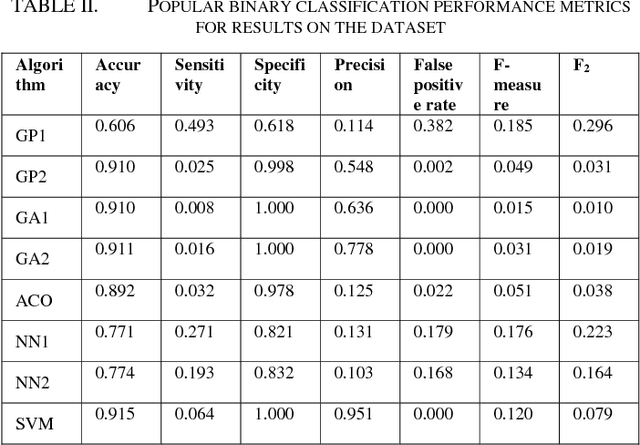

Financial fraud detection is an important problem with a number of design aspects to consider. Issues such as algorithm selection and performance analysis will affect the perceived ability of proposed solutions, so for auditors and re-searchers to be able to sufficiently detect financial fraud it is necessary that these issues be thoroughly explored. In this paper we will revisit the key performance metrics used for financial fraud detection with a focus on credit card fraud, critiquing the prevailing ideas and offering our own understandings. There are many different performance metrics that have been employed in prior financial fraud detection research. We will analyse several of the popular metrics and compare their effectiveness at measuring the ability of detection mechanisms. We further investigated the performance of a range of computational intelligence techniques when applied to this problem domain, and explored the efficacy of several binary classification methods.
Evolutionary Landscape and Management of Population Diversity
Oct 24, 2015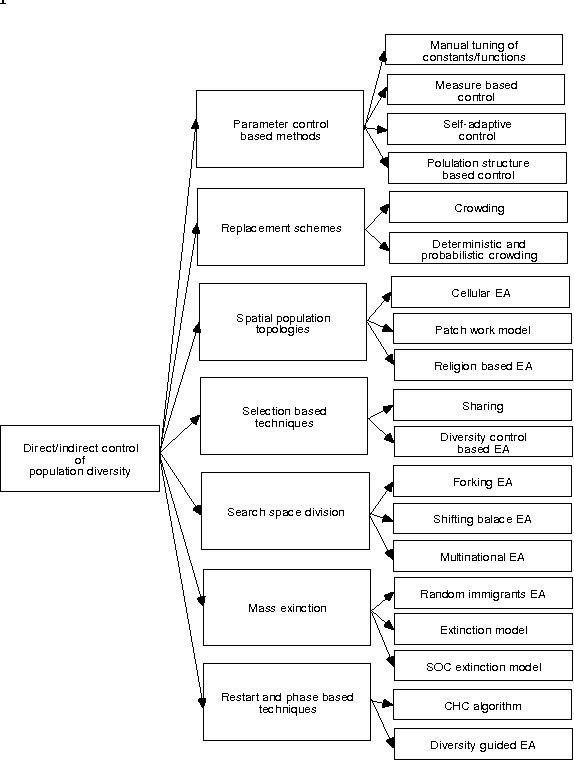



The search ability of an Evolutionary Algorithm (EA) depends on the variation among the individuals in the population [3, 4, 8]. Maintaining an optimal level of diversity in the EA population is imperative to ensure that progress of the EA search is unhindered by premature convergence to suboptimal solutions. Clearer understanding of the concept of population diversity, in the context of evolutionary search and premature convergence in particular, is the key to designing efficient EAs. To this end, this paper first presents a brief analysis of the EA population diversity issues. Next we present an investigation on a counter-niching EA technique [4] that introduces and maintains constructive diversity in the population. The proposed approach uses informed genetic operations to reach promising, but unexplored or under-explored areas of the search space, while discouraging premature local convergence. Simulation runs on a suite of standard benchmark test functions with Genetic Algorithm (GA) implementation shows promising results.
Uncertainty And Evolutionary Optimization: A Novel Approach
Nov 21, 2014
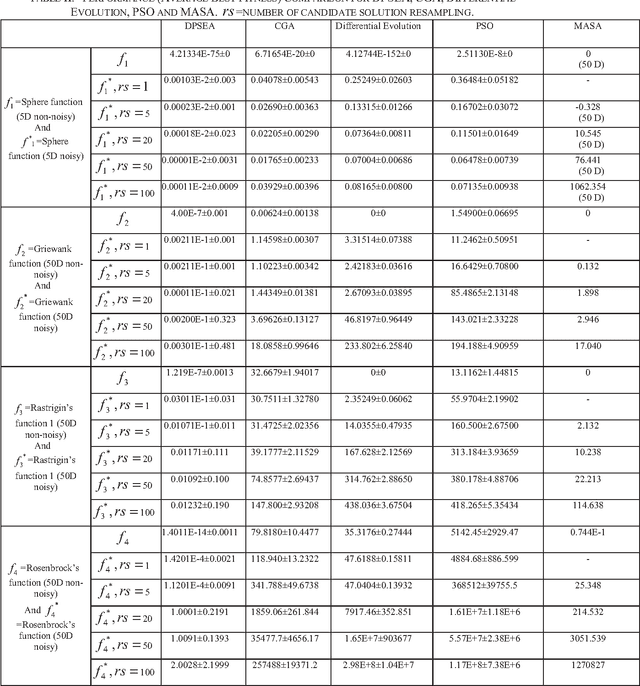


Evolutionary algorithms (EA) have been widely accepted as efficient solvers for complex real world optimization problems, including engineering optimization. However, real world optimization problems often involve uncertain environment including noisy and/or dynamic environments, which pose major challenges to EA-based optimization. The presence of noise interferes with the evaluation and the selection process of EA, and thus adversely affects its performance. In addition, as presence of noise poses challenges to the evaluation of the fitness function, it may need to be estimated instead of being evaluated. Several existing approaches attempt to address this problem, such as introduction of diversity (hyper mutation, random immigrants, special operators) or incorporation of memory of the past (diploidy, case based memory). However, these approaches fail to adequately address the problem. In this paper we propose a Distributed Population Switching Evolutionary Algorithm (DPSEA) method that addresses optimization of functions with noisy fitness using a distributed population switching architecture, to simulate a distributed self-adaptive memory of the solution space. Local regression is used in the pseudo-populations to estimate the fitness. Successful applications to benchmark test problems ascertain the proposed method's superior performance in terms of both robustness and accuracy.
Diversity Handling In Evolutionary Landscape
Nov 15, 2014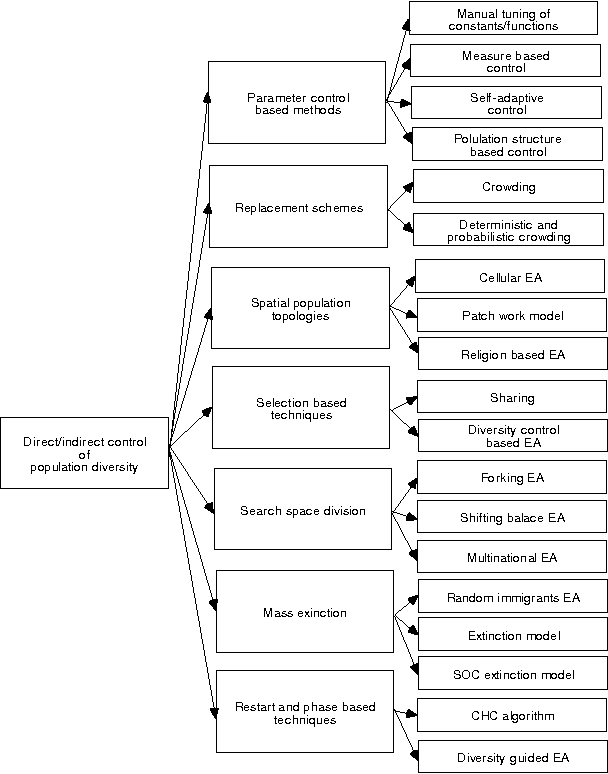
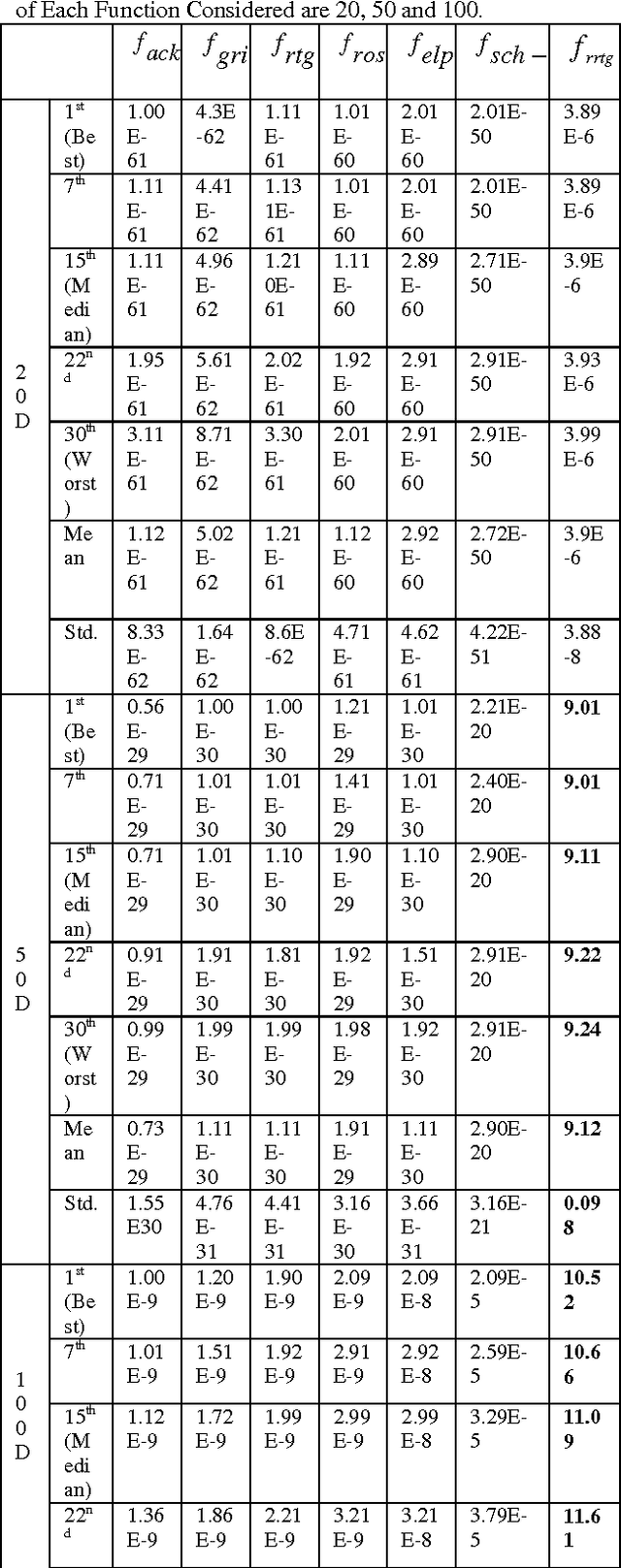


The search ability of an Evolutionary Algorithm (EA) depends on the variation among the individuals in the population. Maintaining an optimal level of diversity in the EA population is imperative to ensure that progress of the EA search is unhindered by premature convergence to suboptimal solutions. Clearer understanding of the concept of population diversity, in the context of evolutionary search and premature convergence in particular, is the key to designing efficient EAs. To this end, this paper first presents a comprehensive analysis of the EA population diversity issues. Next we present an investigation on a counter-niching EA technique that introduces and maintains constructive diversity in the population. The proposed approach uses informed genetic operations to reach promising, but un-explored or under-explored areas of the search space, while discouraging premature local convergence. Simulation runs on a number of standard benchmark test functions with Genetic Algorithm (GA) implementation shows promising results.
Bioclimating Modelling: A Machine Learning Perspective
Jun 18, 2013



Many machine learning (ML) approaches are widely used to generate bioclimatic models for prediction of geographic range of organism as a function of climate. Applications such as prediction of range shift in organism, range of invasive species influenced by climate change are important parameters in understanding the impact of climate change. However, success of machine learning-based approaches depends on a number of factors. While it can be safely said that no particular ML technique can be effective in all applications and success of a technique is predominantly dependent on the application or the type of the problem, it is useful to understand their behaviour to ensure informed choice of techniques. This paper presents a comprehensive review of machine learning-based bioclimatic model generation and analyses the factors influencing success of such models. Considering the wide use of statistical techniques, in our discussion we also include conventional statistical techniques used in bioclimatic modelling.
Evolutionary Approaches to Expensive Optimisation
Mar 12, 2013

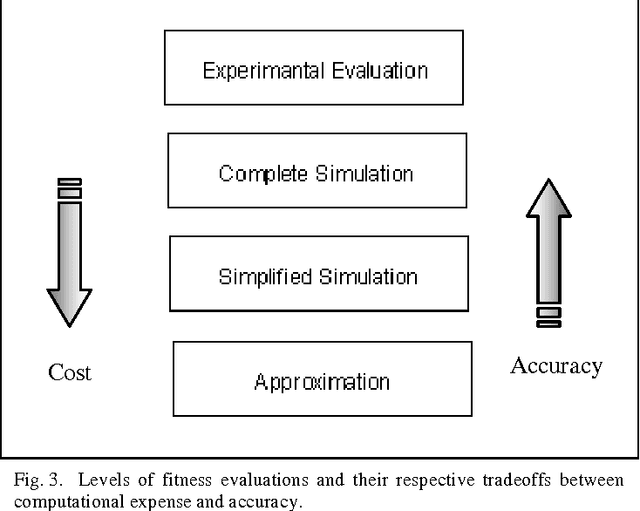
Surrogate assisted evolutionary algorithms (EA) are rapidly gaining popularity where applications of EA in complex real world problem domains are concerned. Although EAs are powerful global optimizers, finding optimal solution to complex high dimensional, multimodal problems often require very expensive fitness function evaluations. Needless to say, this could brand any population-based iterative optimization technique to be the most crippling choice to handle such problems. Use of approximate model or surrogates provides a much cheaper option. However, naturally this cheaper option comes with its own price. This paper discusses some of the key issues involved with use of approximation in evolutionary algorithm, possible best practices and solutions. Answers to the following questions have been sought: what type of fitness approximation to be used; which approximation model to use; how to integrate the approximation model in EA; how much approximation to use; and how to ensure reliable approximation.
* 7 pages
Machine Learning for Bioclimatic Modelling
Mar 12, 2013


Many machine learning (ML) approaches are widely used to generate bioclimatic models for prediction of geographic range of organism as a function of climate. Applications such as prediction of range shift in organism, range of invasive species influenced by climate change are important parameters in understanding the impact of climate change. However, success of machine learning-based approaches depends on a number of factors. While it can be safely said that no particular ML technique can be effective in all applications and success of a technique is predominantly dependent on the application or the type of the problem, it is useful to understand their behavior to ensure informed choice of techniques. This paper presents a comprehensive review of machine learning-based bioclimatic model generation and analyses the factors influencing success of such models. Considering the wide use of statistical techniques, in our discussion we also include conventional statistical techniques used in bioclimatic modelling.
* 8 pages
Expensive Optimisation: A Metaheuristics Perspective
Mar 09, 2013

Stochastic, iterative search methods such as Evolutionary Algorithms (EAs) are proven to be efficient optimizers. However, they require evaluation of the candidate solutions which may be prohibitively expensive in many real world optimization problems. Use of approximate models or surrogates is being explored as a way to reduce the number of such evaluations. In this paper we investigated three such methods. The first method (DAFHEA) partially replaces an expensive function evaluation by its approximate model. The approximation is realized with support vector machine (SVM) regression models. The second method (DAFHEA II) is an enhancement on DAFHEA to accommodate for uncertain environments. The third one uses surrogate ranking with preference learning or ordinal regression. The fitness of the candidates is estimated by modeling their rank. The techniques' performances on some of the benchmark numerical optimization problems have been reported. The comparative benefits and shortcomings of both techniques have been identified.
* 7 pages