 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Machine Inference for Robotic Manipulation
Dec 13, 2024Learning from Demonstrations (LfD) and Reinforcement Learning (RL) have enabled robot agents to accomplish complex tasks. Reward Machines (RMs) enhance RL's capability to train policies over extended time horizons by structuring high-level task information. In this work, we introduce a novel LfD approach for learning RMs directly from visual demonstrations of robotic manipulation tasks. Unlike previous methods, our approach requires no predefined propositions or prior knowledge of the underlying sparse reward signals. Instead, it jointly learns the RM structure and identifies key high-level events that drive transitions between RM states. We validate our method on vision-based manipulation tasks, showing that the inferred RM accurately captures task structure and enables an RL agent to effectively learn an optimal policy.
Learning Safety Constraints From Demonstration Using One-Class Decision Trees
Dec 14, 2023The alignment of autonomous agents with human values is a pivotal challenge when deploying these agents within physical environments, where safety is an important concern. However, defining the agent's objective as a reward and/or cost function is inherently complex and prone to human errors. In response to this challenge, we present a novel approach that leverages one-class decision trees to facilitate learning from expert demonstrations. These decision trees provide a foundation for representing a set of constraints pertinent to the given environment as a logical formula in disjunctive normal form. The learned constraints are subsequently employed within an oracle constrained reinforcement learning framework, enabling the acquisition of a safe policy. In contrast to other methods, our approach offers an interpretable representation of the constraints, a vital feature in safety-critical environments. To validate the effectiveness of our proposed method, we conduct experiments in synthetic benchmark domains and a realistic driving environment.
Maximum Causal Entropy Inverse Constrained Reinforcement Learning
May 04, 2023When deploying artificial agents in real-world environments where they interact with humans, it is crucial that their behavior is aligned with the values, social norms or other requirements of that environment. However, many environments have implicit constraints that are difficult to specify and transfer to a learning agent. To address this challenge, we propose a novel method that utilizes the principle of maximum causal entropy to learn constraints and an optimal policy that adheres to these constraints, using demonstrations of agents that abide by the constraints. We prove convergence in a tabular setting and provide an approximation which scales to complex environments. We evaluate the effectiveness of the learned policy by assessing the reward received and the number of constraint violations, and we evaluate the learned cost function based on its transferability to other agents. Our method has been shown to outperform state-of-the-art approaches across a variety of tasks and environments, and it is able to handle problems with stochastic dynamics and a continuous state-action space.
Intelligent Frame Selection as a Privacy-Friendlier Alternative to Face Recognition
Jan 27, 2021

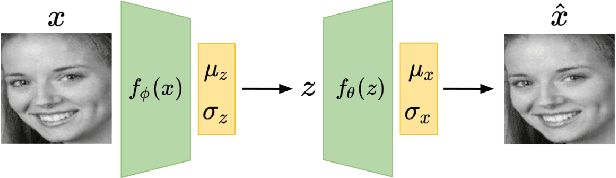

The widespread deployment of surveillance cameras for facial recognition gives rise to many privacy concerns. This study proposes a privacy-friendly alternative to large scale facial recognition. While there are multiple techniques to preserve privacy, our work is based on the minimization principle which implies minimizing the amount of collected personal data. Instead of running facial recognition software on all video data, we propose to automatically extract a high quality snapshot of each detected person without revealing his or her identity. This snapshot is then encrypted and access is only granted after legal authorization. We introduce a novel unsupervised face image quality assessment method which is used to select the high quality snapshots. For this, we train a variational autoencoder on high quality face images from a publicly available dataset and use the reconstruction probability as a metric to estimate the quality of each face crop. We experimentally confirm that the reconstruction probability can be used as biometric quality predictor. Unlike most previous studies, we do not rely on a manually defined face quality metric as everything is learned from data. Our face quality assessment method outperforms supervised, unsupervised and general image quality assessment methods on the task of improving face verification performance by rejecting low quality images. The effectiveness of the whole system is validated qualitatively on still images and videos.