 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Domain Adaptation Enables Knowledge Transfer Across Heterogeneous RNA-Seq Datasets
Mar 09, 2026Accurate phenotype prediction from RNA sequencing (RNA-seq) data is essential for diagnosis, biomarker discovery, and personalized medicine. Deep learning models have demonstrated strong potential to outperform classical machine learning approaches, but their performance relies on large, well-annotated datasets. In transcriptomics, such datasets are frequently limited, leading to over-fitting and poor generalization. Knowledge transfer from larger, more general datasets can alleviate this issue. However, transferring information across RNA-seq datasets remains challenging due to heterogeneous preprocessing pipelines and differences in target phenotypes. In this study, we propose a deep learning-based domain adaptation framework that enables effective knowledge transfer from a large general dataset to a smaller one for cancer type classification. The method learns a domain-invariant latent space by jointly optimizing classification and domain alignment objectives. To ensure stable training and robustness in data-scarce scenarios, the framework is trained with an adversarial approach with appropriate regularization. Both supervised and unsupervised approach variants are explored, leveraging labeled or unlabeled target samples. The framework is evaluated on three large-scale transcriptomic datasets (TCGA, ARCHS4, GTEx) to assess its ability to transfer knowledge across cohorts. Experimental results demonstrate consistent improvements in cancer and tissue type classification accuracy compared to non-adaptive baselines, particularly in low-data scenarios. Overall, this work highlights domain adaptation as a powerful strategy for data-efficient knowledge transfer in transcriptomics, enabling robust phenotype prediction under constrained data conditions.
On the Necessity of Metalearning: Learning Suitable Parameterizations for Learning Processes
Dec 31, 2023In this paper we will discuss metalearning and how we can go beyond the current classical learning paradigm. We will first address the importance of inductive biases in the learning process and what is at stake: the quantities of data necessary to learn. We will subsequently see the importance of choosing suitable parameterizations to end up with well-defined learning processes. Especially since in the context of real-world applications, we face numerous biases due, e.g., to the specificities of sensors, the heterogeneity of data sources, the multiplicity of points of view, etc. This will lead us to the idea of exploiting the structuring of the concepts to be learned in order to organize the learning process that we published previously. We conclude by discussing the perspectives around parameter-tying schemes and the emergence of universal aspects in the models thus learned.
Affinity-Based Hierarchical Learning of Dependent Concepts for Human Activity Recognition
Apr 11, 2021



In multi-class classification tasks, like human activity recognition, it is often assumed that classes are separable. In real applications, this assumption becomes strong and generates inconsistencies. Besides, the most commonly used approach is to learn classes one-by-one against the others. This computational simplification principle introduces strong inductive biases on the learned theories. In fact, the natural connections among some classes, and not others, deserve to be taken into account. In this paper, we show that the organization of overlapping classes (multiple inheritances) into hierarchies considerably improves classification performances. This is particularly true in the case of activity recognition tasks featured in the SHL dataset. After theoretically showing the exponential complexity of possible class hierarchies, we propose an approach based on transfer affinity among the classes to determine an optimal hierarchy for the learning process. Extensive experiments show improved performances and a reduction in the number of examples needed to learn.
Description of Structural Biases and Associated Data in Sensor-Rich Environments
Apr 11, 2021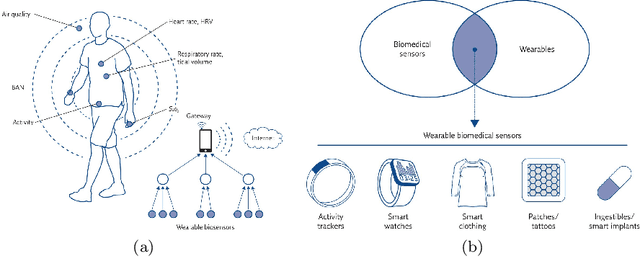
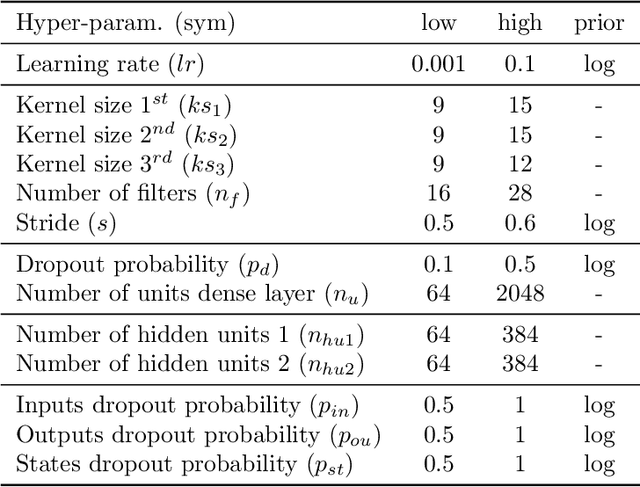
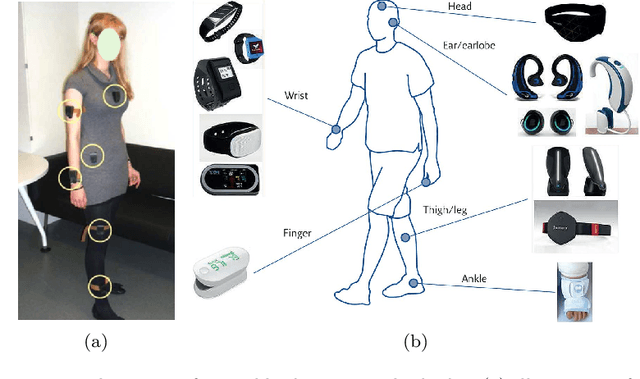
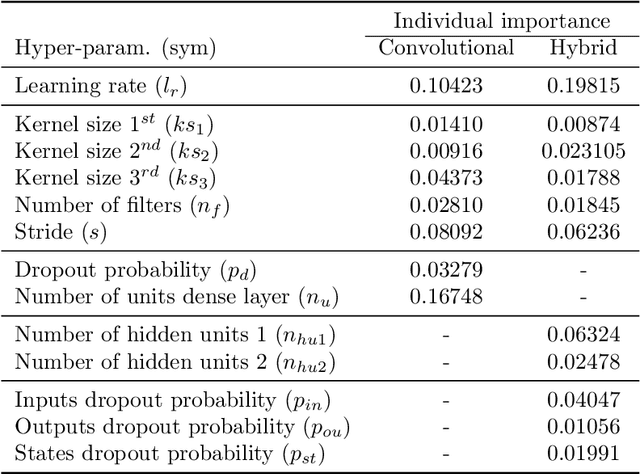
In this article, we study activity recognition in the context of sensor-rich environments. We address, in particular, the problem of inductive biases and their impact on the data collection process. To be effective and robust, activity recognition systems must take these biases into account at all levels and model them as hyperparameters by which they can be controlled. Whether it is a bias related to sensor measurement, transmission protocol, sensor deployment topology, heterogeneity, dynamicity, or stochastic effects, it is important to understand their substantial impact on the quality of activity recognition models. This study highlights the need to separate the different types of biases arising in real situations so that machine learning models, e.g., adapt to the dynamicity of these environments, resist to sensor failures, and follow the evolution of the sensors topology. We propose a metamodeling process in which the sensor data is structured in layers. The lower layers encode the various biases linked to transformations, transmissions, and topology of data. The upper layers encode biases related to the data itself. This way, it becomes easier to model hyperparameters and follow changes in the data acquisition infrastructure. We illustrate our approach on the SHL dataset which provides motion sensor data for a list of human activities collected under real conditions. The trade-offs exposed and the broader implications of our approach are discussed with alternative techniques to encode and incorporate knowledge into activity recognition models.