 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Tiger: Inference Attacks on Split Learning
Dec 04, 2020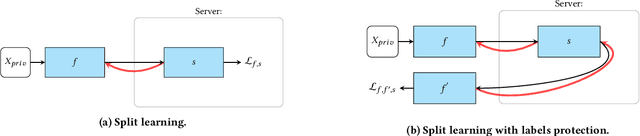
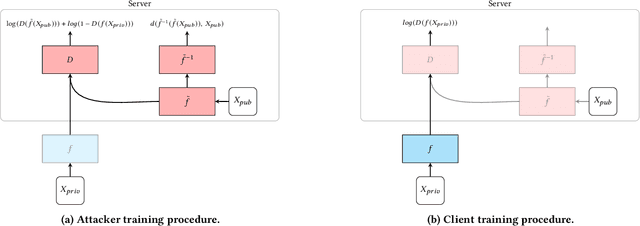

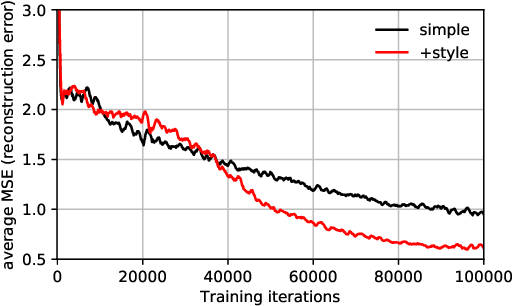
We investigate the security of split learning -- a novel collaborative machine learning framework that enables peak performance by requiring minimal resources consumption. In the paper, we make explicit the vulnerabilities of the protocol and demonstrate its inherent insecurity by introducing general attack strategies targeting the reconstruction of clients' private training sets. More prominently, we demonstrate that a malicious server can actively hijack the learning process of the distributed model and bring it into an insecure state that enables inference attacks on clients' data. We implement different adaptations of the attack and test them on various datasets as well as within realistic threat scenarios. To make our results reproducible, we made our code available at https://github.com/pasquini-dario/SplitNN_FSHA.
Reducing Bias in Modeling Real-world Password Strength via Deep Learning and Dynamic Dictionaries
Oct 26, 2020
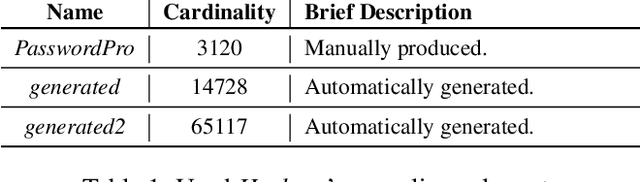
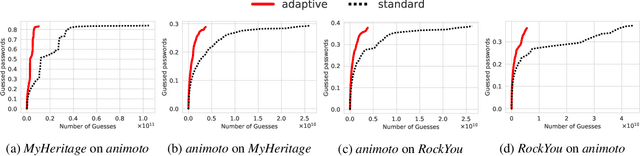

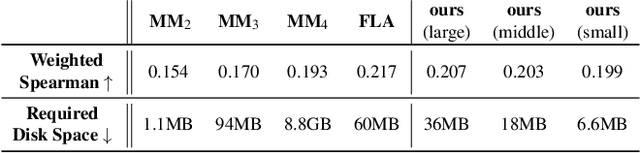
Password security hinges on an accurate understanding of the techniques adopted by attackers. However, current studies mostly rely on probabilistic password models that are imperfect proxies of real-world guessing strategies. The main reason is that attackers rely on very pragmatic approaches such as dictionary attacks. Unfortunately, it is inherently difficult to correctly model those methods. To be representative, dictionary attacks must be thoughtfully configured according to a process that requires an expertise that cannot be easily replicated in password studies. The consequence of inaccurately calibrating those attacks is the unreliability of password security estimates, impaired by measurement bias. In the present work, we introduce new guessing techniques that make dictionary attacks consistently more resilient to inadequate configurations. Our framework allows dictionary attacks to self-heal and converge towards optimal attacks' performance, requiring no supervision or domain-knowledge. To achieve this: (1) We use a deep neural network to model and then simulate the proficiency of expert adversaries. (2) Then, we introduce automatic dynamic strategies within dictionary attacks to mimic experts' ability to adapt their guessing strategies on the fly by incorporating knowledge on their targets. Our techniques enable robust and sound password strength estimates, eventually reducing bias in modeling real-world threats in password security.
Interpretable Probabilistic Password Strength Meters via Deep Learning
Apr 29, 2020
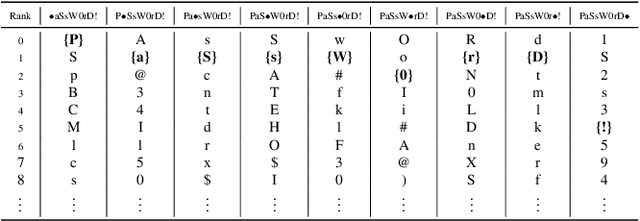

Probabilistic password strength meters have been proved to be the most accurate tools to measure password strength. Unfortunately, by construction, they are limited to solely produce an opaque security estimation that fails to fully support the user during the password composition. In the present work, we move the first steps towards cracking the intelligibility barrier of this compelling class of meters. We show that probabilistic password meters inherently own the capability of describing the latent relation occurring between password strength and password structure. In our approach, the security contribution of each character composing a password is disentangled and used to provide explicit fine-grained feedback for the user. Furthermore, unlike existing heuristic constructions, our method is free from any human bias, and, more importantly, its feedback has a clear probabilistic interpretation. In our contribution: (1) we formulate the theoretical foundations of interpretable probabilistic password strength meters; (2) we describe how they can be implemented via an efficient and lightweight deep learning framework suitable for client-side operability.
Out-domain examples for generative models
Mar 07, 2019



Deep generative models are being increasingly used in a wide variety of applications. However, the generative process is not fully predictable and at times, it produces an unexpected output. We will refer to those outputs as out-domain examples. In the present paper we show that an attacker can force a pre-trained generator to reproduce an arbitrary out-domain example if fed by a suitable adversarial input. The main assumption is that those outputs lie in an unexplored region of the generator's codomain and hence they have a very low probability of being naturally generated. Moreover, we show that this adversarial input can be shaped so as to be statistically indistinguishable from the set of genuine inputs. The goal is to look for an efficient way of finding these inputs in the generator's latent space.