 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwim: A General-Purpose, High-Performing, and Efficient Activation Function for Locomotion Control Tasks
Mar 05, 2023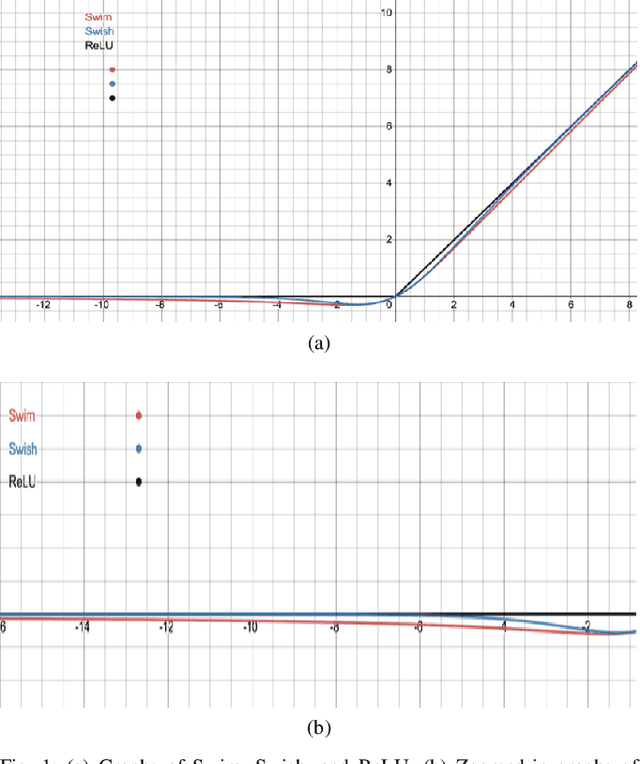
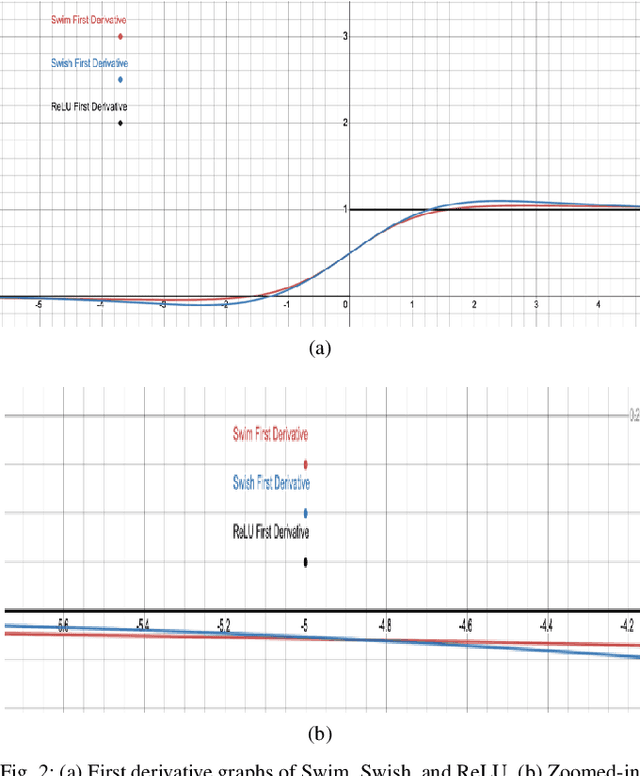
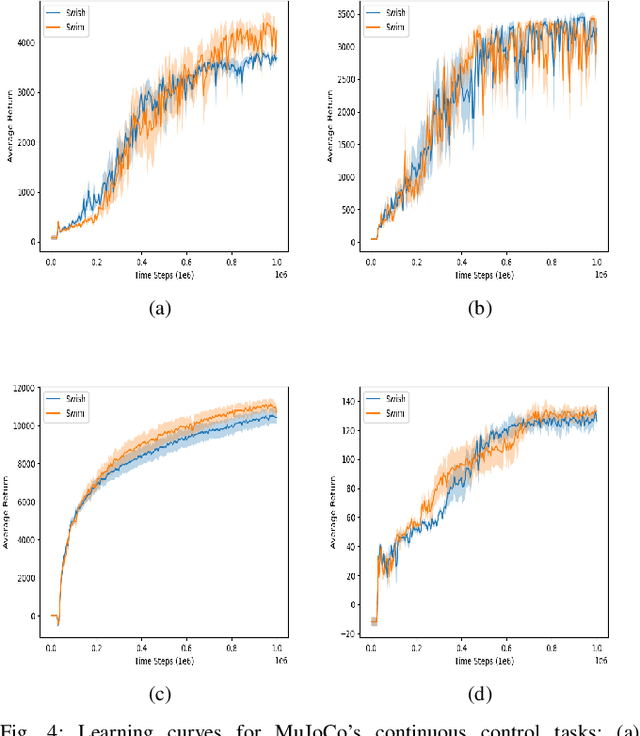
Activation functions play a significant role in the performance of deep learning algorithms. In particular, the Swish activation function tends to outperform ReLU on deeper models, including deep reinforcement learning models, across challenging tasks. Despite this progress, ReLU is the preferred function partly because it is more efficient than Swish. Furthermore, in contrast to the fields of computer vision and natural language processing, the deep reinforcement learning and robotics domains have seen less inclination to adopt new activation functions, such as Swish, and instead continue to use more traditional functions, like ReLU. To tackle those issues, we propose Swim, a general-purpose, efficient, and high-performing alternative to Swish, and then provide an analysis of its properties as well as an explanation for its high-performance relative to Swish, in terms of both reward-achievement and efficiency. We focus on testing Swim on MuJoCo's locomotion continuous control tasks since they exhibit more complex dynamics and would therefore benefit most from a high-performing and efficient activation function. We also use the TD3 algorithm in conjunction with Swim and explain this choice in the context of the robot locomotion domain. We then conclude that Swim is a state-of-the-art activation function for continuous control locomotion tasks and recommend using it with TD3 as a working framework.