 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning intuitive physics and one-shot imitation using state-action-prediction self-organizing maps
Jul 03, 2020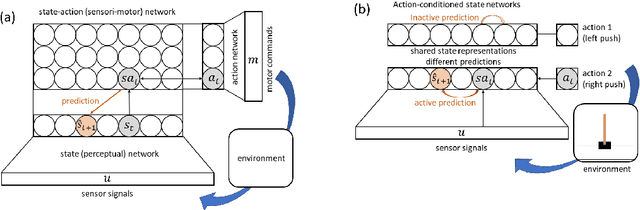
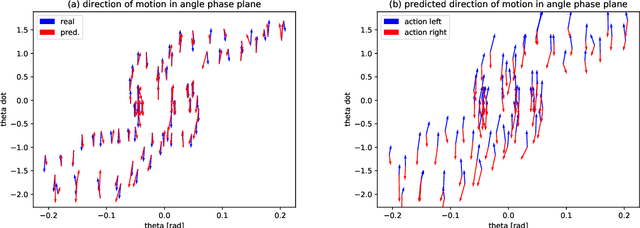
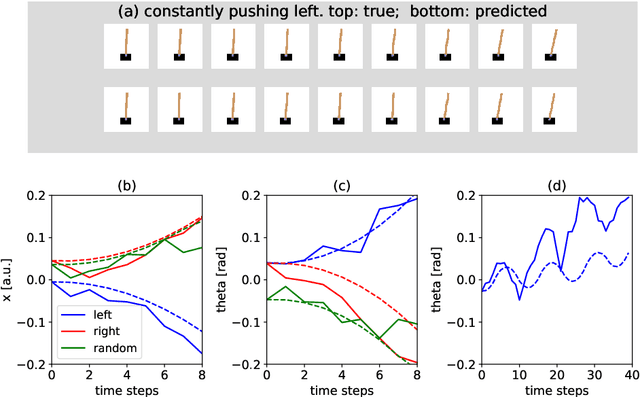
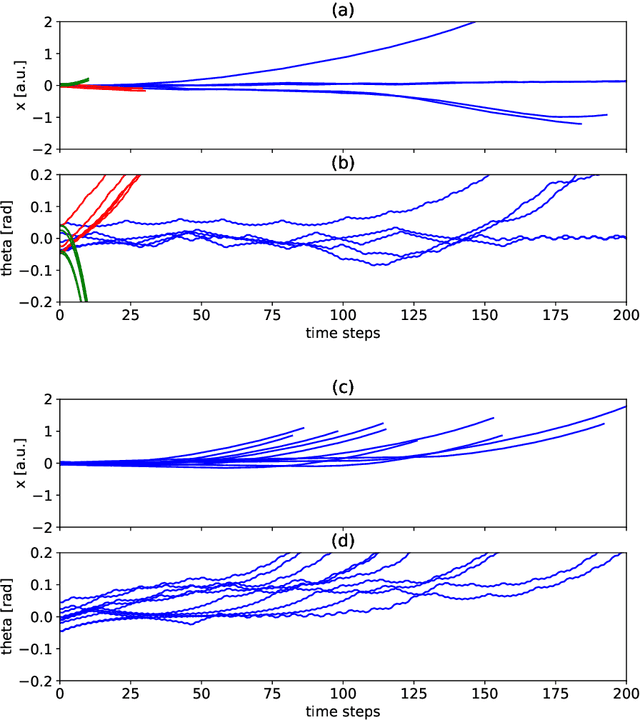
Human learning and intelligence work differently from the supervised pattern recognition approach adopted in most deep learning architectures. Humans seem to learn rich representations by exploration and imitation, build causal models of the world, and use both to flexibly solve new tasks. We suggest a simple but effective unsupervised model which develops such characteristics. The agent learns to represent the dynamical physical properties of its environment by intrinsically motivated exploration, and performs inference on this representation to reach goals. For this, a set of self-organizing maps which represent state-action pairs is combined with a causal model for sequence prediction. The proposed system is evaluated in the cartpole environment. After an initial phase of playful exploration, the agent can execute kinematic simulations of the environment's future, and use those for action planning. We demonstrate its performance on a set of several related, but different one-shot imitation tasks, which the agent flexibly solves in an active inference style.