 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTermiNeRF: Ray Termination Prediction for Efficient Neural Rendering
Nov 05, 2021
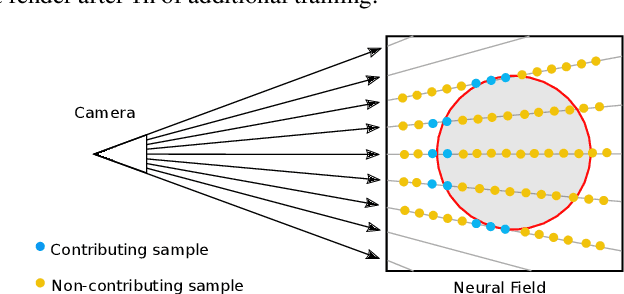

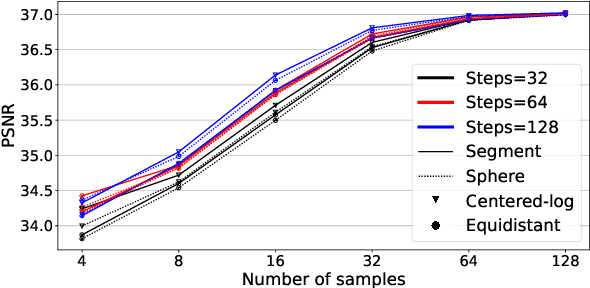
Volume rendering using neural fields has shown great promise in capturing and synthesizing novel views of 3D scenes. However, this type of approach requires querying the volume network at multiple points along each viewing ray in order to render an image, resulting in very slow rendering times. In this paper, we present a method that overcomes this limitation by learning a direct mapping from camera rays to locations along the ray that are most likely to influence the pixel's final appearance. Using this approach we are able to render, train and fine-tune a volumetrically-rendered neural field model an order of magnitude faster than standard approaches. Unlike existing methods, our approach works with general volumes and can be trained end-to-end.