 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Encoder-BoF/HMM System for Arabic Text Recognition
Jan 08, 2019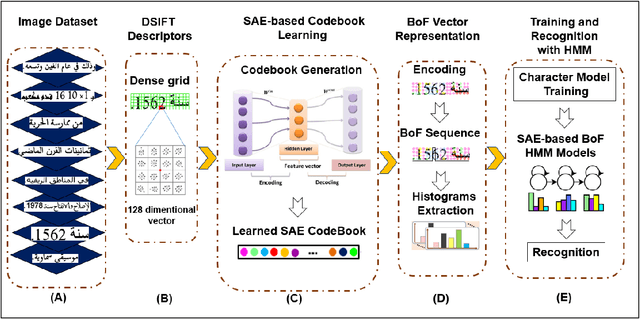


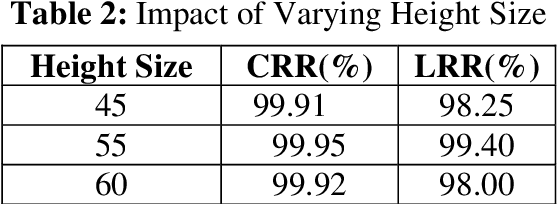
The recognition of Arabic text, in both handwritten and printed forms, represents a fertile provenance of technical difficulties for Optical Character Recognition (OCR). Indeed, the printed is commonly governed by well-established calligraphy rules and the characters are well aligned. However, there is not always a system capable of reading Arabic printed text in an unconstrained environments such as unlimited vocabulary, multi styles, mixed-font and their great morphological variability. This diversity complicates the choice of features to extract and algorithm of segmentation. In this context, we adopt a new solution for unlimited-vocabulary and mixed-font Arabic printed text recognition. The proposed system is based on the adoption of Bag of Features (BoF) model using Sparse Auto-Encoder (SAE) for features representation and Hidden Markov Models (HMM) for recognition. As results, the obtained average accuracies of recognition vary between 99.65% and 99.96% for the mono-font and exceed 99% for mixed-font.
Multilingual Scene Character Recognition System using Sparse Auto-Encoder for Efficient Local Features Representation in Bag of Features
Jul 19, 2018

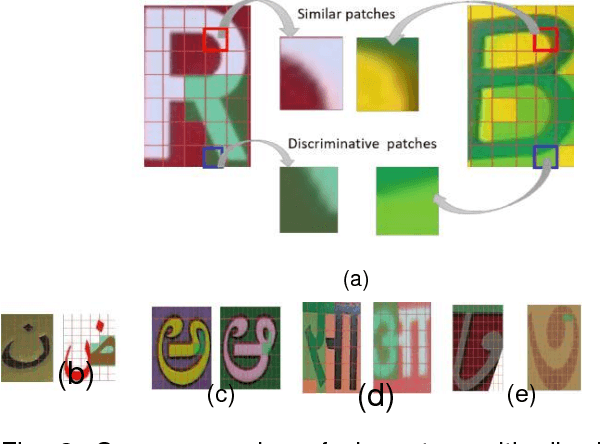

The recognition of texts existing in camera-captured images has become an important issue for a great deal of research during the past few decades. This give birth to Scene Character Recognition (SCR) which is an important step in scene text recognition pipeline. In this paper, we extended the Bag of Features (BoF)-based model using deep learning for representing features for accurate SCR of different languages. In the features coding step, a deep Sparse Auto-encoder (SAE)-based strategy was applied to enhance the representative and discriminative abilities of image features. This deep learning architecture provides more efficient features representation and therefore a better recognition accuracy. Our system was evaluated extensively on all the scene character datasets of five different languages. The experimental results proved the efficiency of our system for a multilingual SCR.