 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: LLM-based Log Parsing
Apr 07, 2025Log data, generated by software systems, provides crucial insights for tasks like monitoring, root cause analysis, and anomaly detection. Due to the vast volume of logs, automated log parsing is essential to transform semi-structured log messages into structured representations. Traditional log parsing techniques often require manual configurations, such as defining log formats or labeling data, which limits scalability and usability. Recent advances in large language models (LLMs) have introduced the new research field of LLM-based log parsing, offering potential improvements in automation and adaptability. Despite promising results, there is no structured overview of these approaches since this is a relatively new research field with the earliest advances published in late 2023. This paper systematically reviews 29 LLM-based log parsing methods, comparing their capabilities, limitations, and reliance on manual effort. We analyze the learning and prompt-engineering paradigms employed, efficiency- and effectiveness-enhancing techniques, and the role of LLMs in the parsing process. We aggregate the results of the survey in a large table comprising the characterizing features of LLM-based log parsing approaches and derive the general process of LLM-based log parsing, incorporating all reviewed approaches in a single flow chart. Additionally, we benchmark seven open-source LLM-based log parsers on public datasets and critically assess their reproducibility. Our findings summarize the advances of this new research field and provide insights for researchers and practitioners seeking efficient and user-friendly log parsing solutions, with all code and results made publicly available for transparency.
A Critical Review of Common Log Data Sets Used for Evaluation of Sequence-based Anomaly Detection Techniques
Sep 06, 2023Log data store event execution patterns that correspond to underlying workflows of systems or applications. While most logs are informative, log data also include artifacts that indicate failures or incidents. Accordingly, log data are often used to evaluate anomaly detection techniques that aim to automatically disclose unexpected or otherwise relevant system behavior patterns. Recently, detection approaches leveraging deep learning have increasingly focused on anomalies that manifest as changes of sequential patterns within otherwise normal event traces. Several publicly available data sets, such as HDFS, BGL, Thunderbird, OpenStack, and Hadoop, have since become standards for evaluating these anomaly detection techniques, however, the appropriateness of these data sets has not been closely investigated in the past. In this paper we therefore analyze six publicly available log data sets with focus on the manifestations of anomalies and simple techniques for their detection. Our findings suggest that most anomalies are not directly related to sequential manifestations and that advanced detection techniques are not required to achieve high detection rates on these data sets.
Deep Learning for Anomaly Detection in Log Data: A Survey
Jul 08, 2022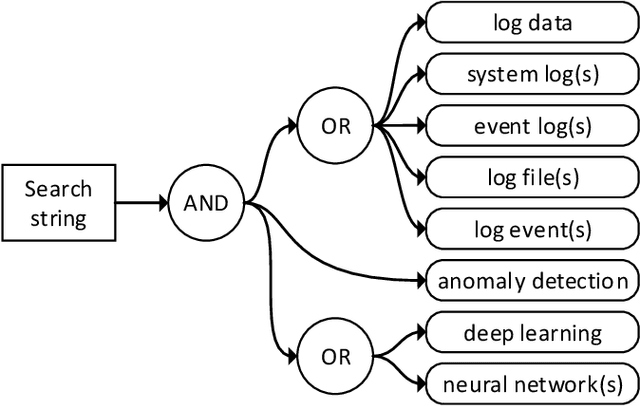
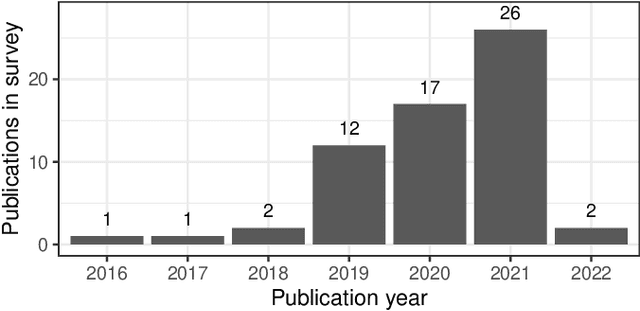


Automatic log file analysis enables early detection of relevant incidents such as system failures. In particular, self-learning anomaly detection techniques capture patterns in log data and subsequently report unexpected log event occurrences to system operators without the need to provide or manually model anomalous scenarios in advance. Recently, an increasing number of approaches leveraging deep learning neural networks for this purpose have been presented. These approaches have demonstrated superior detection performance in comparison to conventional machine learning techniques and simultaneously resolve issues with unstable data formats. However, there exist many different architectures for deep learning and it is non-trivial to encode raw and unstructured log data to be analyzed by neural networks. We therefore carry out a systematic literature review that provides an overview of deployed models, data pre-processing mechanisms, anomaly detection techniques, and evaluations. The survey does not quantitatively compare existing approaches but instead aims to help readers understand relevant aspects of different model architectures and emphasizes open issues for future work.