 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomized Video QoE Estimation with Algorithm-Agnostic Transfer Learning
Mar 12, 2020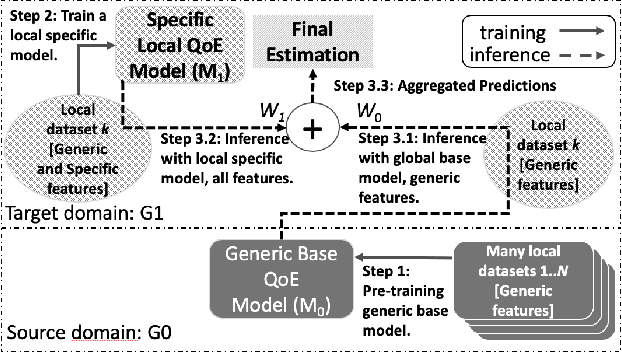
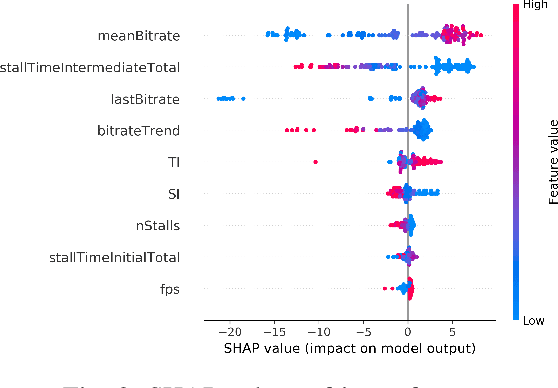
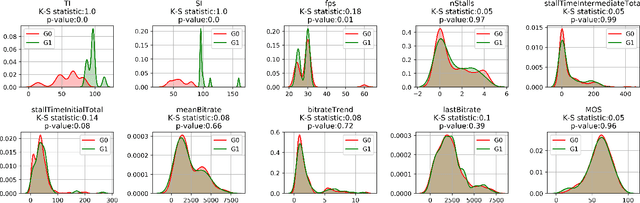
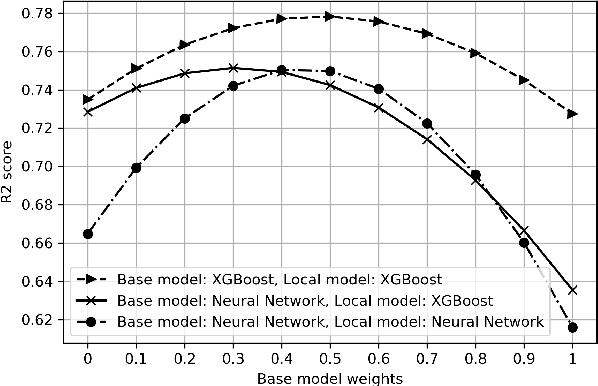
The development of QoE models by means of Machine Learning (ML) is challenging, amongst others due to small-size datasets, lack of diversity in user profiles in the source domain, and too much diversity in the target domains of QoE models. Furthermore, datasets can be hard to share between research entities, as the machine learning models and the collected user data from the user studies may be IPR- or GDPR-sensitive. This makes a decentralized learning-based framework appealing for sharing and aggregating learned knowledge in-between the local models that map the obtained metrics to the user QoE, such as Mean Opinion Scores (MOS). In this paper, we present a transfer learning-based ML model training approach, which allows decentralized local models to share generic indicators on MOS to learn a generic base model, and then customize the generic base model further using additional features that are unique to those specific localized (and potentially sensitive) QoE nodes. We show that the proposed approach is agnostic to specific ML algorithms, stacked upon each other, as it does not necessitate the collaborating localized nodes to run the same ML algorithm. Our reproducible results reveal the advantages of stacking various generic and specific models with corresponding weight factors. Moreover, we identify the optimal combination of algorithms and weight factors for the corresponding localized QoE nodes.
Privacy Preserving QoE Modeling using Collaborative Learning
Jun 26, 2019
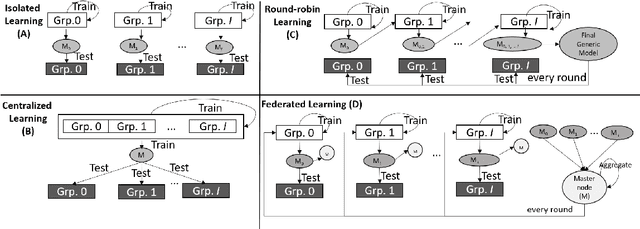

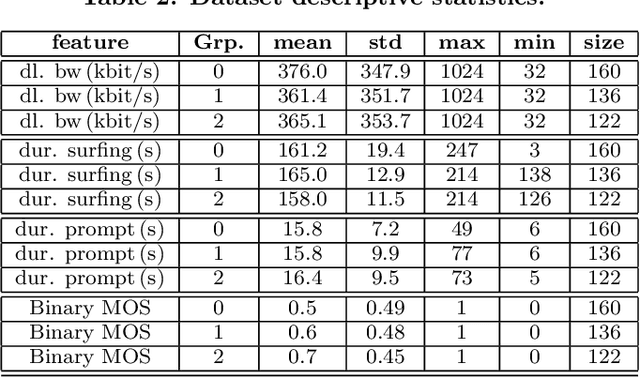
Machine Learning based Quality of Experience (QoE) models potentially suffer from over-fitting due to limitations including low data volume, and limited participant profiles. This prevents models from becoming generic. Consequently, these trained models may under-perform when tested outside the experimented population. One reason for the limited datasets, which we refer in this paper as small QoE data lakes, is due to the fact that often these datasets potentially contain user sensitive information and are only collected throughout expensive user studies with special user consent. Thus, sharing of datasets amongst researchers is often not allowed. In recent years, privacy preserving machine learning models have become important and so have techniques that enable model training without sharing datasets but instead relying on secure communication protocols. Following this trend, in this paper, we present Round-Robin based Collaborative Machine Learning model training, where the model is trained in a sequential manner amongst the collaborated partner nodes. We benchmark this work using our customized Federated Learning mechanism as well as conventional Centralized and Isolated Learning methods.