 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying recent advances in Visual Question Answering to Record Linkage
Jul 12, 2020



Multi-modal Record Linkage is the process of matching multi-modal records from multiple sources that represent the same entity. This field has not been explored in research and we propose two solutions based on Deep Learning architectures that are inspired by recent work in Visual Question Answering. The neural networks we propose use two different fusion modules, the Recurrent Neural Network + Convolutional Neural Network fusion module and the Stacked Attention Network fusion module, that jointly combine the visual and the textual data of the records. The output of these fusion models is the input of a Siamese Neural Network that computes the similarity of the records. Using data from the Avito Duplicate Advertisements Detection dataset, we train these solutions and from the experiments, we concluded that the Recurrent Neural Network + Convolutional Neural Network fusion module outperforms a simple model that uses hand-crafted features. We also find that the Recurrent Neural Network + Convolutional Neural Network fusion module classifies dissimilar advertisements as similar more frequently if their average description is bigger than 40 words. We conclude that the reason for this is that the longer advertisements have a different distribution then the shorter advertisements who are more prevalent in the dataset. In the end, we also conclude that further research needs to be done with the Stacked Attention Network, to further explore the effects of the visual data on the performance of the fusion modules.
Stories for Images-in-Sequence by using Visual and Narrative Components
Sep 22, 2018
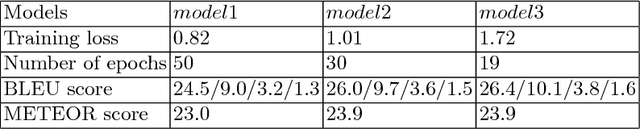
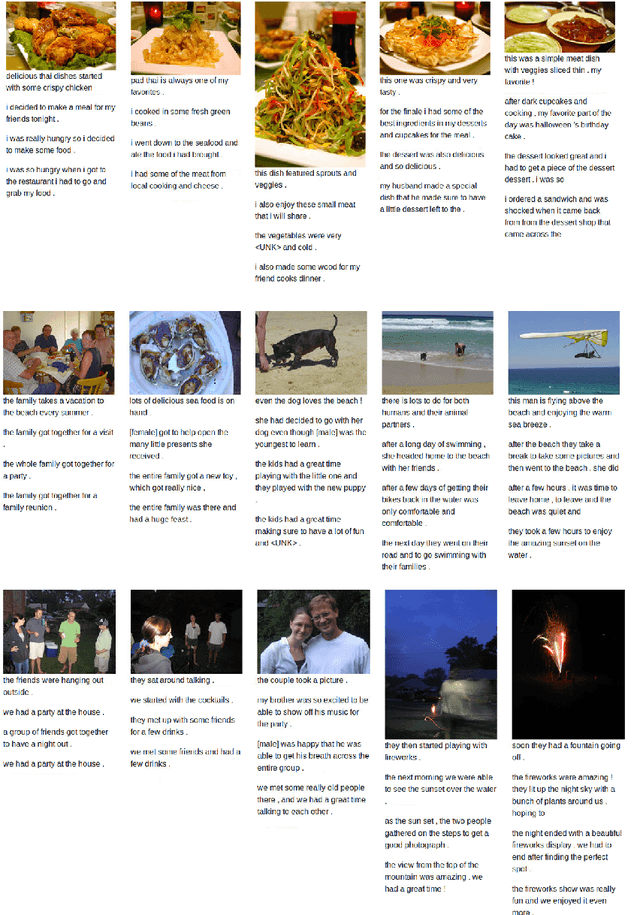
Recent research in AI is focusing towards generating narrative stories about visual scenes. It has the potential to achieve more human-like understanding than just basic description generation of images- in-sequence. In this work, we propose a solution for generating stories for images-in-sequence that is based on the Sequence to Sequence model. As a novelty, our encoder model is composed of two separate encoders, one that models the behaviour of the image sequence and other that models the sentence-story generated for the previous image in the sequence of images. By using the image sequence encoder we capture the temporal dependencies between the image sequence and the sentence-story and by using the previous sentence-story encoder we achieve a better story flow. Our solution generates long human-like stories that not only describe the visual context of the image sequence but also contains narrative and evaluative language. The obtained results were confirmed by manual human evaluation.
* 12 pages, 4 figures, ICT Innovations 2018