 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark Dataset for Tornado Detection and Prediction using Full-Resolution Polarimetric Weather Radar Data
Jan 26, 2024Weather radar is the primary tool used by forecasters to detect and warn for tornadoes in near-real time. In order to assist forecasters in warning the public, several algorithms have been developed to automatically detect tornadic signatures in weather radar observations. Recently, Machine Learning (ML) algorithms, which learn directly from large amounts of labeled data, have been shown to be highly effective for this purpose. Since tornadoes are extremely rare events within the corpus of all available radar observations, the selection and design of training datasets for ML applications is critical for the performance, robustness, and ultimate acceptance of ML algorithms. This study introduces a new benchmark dataset, TorNet to support development of ML algorithms in tornado detection and prediction. TorNet contains full-resolution, polarimetric, Level-II WSR-88D data sampled from 10 years of reported storm events. A number of ML baselines for tornado detection are developed and compared, including a novel deep learning (DL) architecture capable of processing raw radar imagery without the need for manual feature extraction required for existing ML algorithms. Despite not benefiting from manual feature engineering or other preprocessing, the DL model shows increased detection performance compared to non-DL and operational baselines. The TorNet dataset, as well as source code and model weights of the DL baseline trained in this work, are made freely available.
Distributed Deep Learning for Precipitation Nowcasting
Aug 28, 2019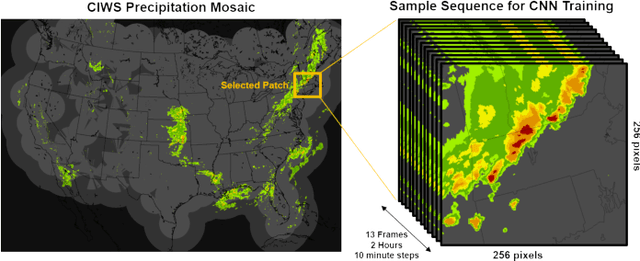
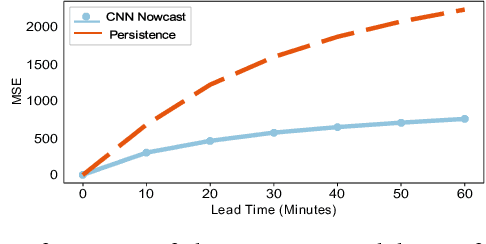

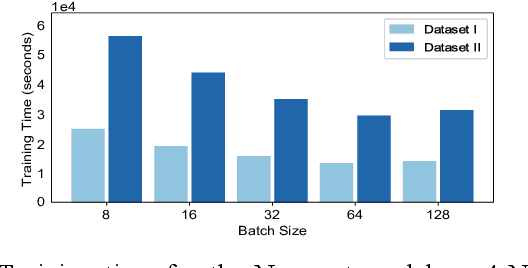
Effective training of Deep Neural Networks requires massive amounts of data and compute. As a result, longer times are needed to train complex models requiring large datasets, which can severely limit research on model development and the exploitation of all available data. In this paper, this problem is investigated in the context of precipitation nowcasting, a term used to describe highly detailed short-term forecasts of precipitation and other hazardous weather. Convolutional Neural Networks (CNNs) are a powerful class of models that are well-suited for this task; however, the high resolution input weather imagery combined with model complexity required to process this data makes training CNNs to solve this task time consuming. To address this issue, a data-parallel model is implemented where a CNN is replicated across multiple compute nodes and the training batches are distributed across multiple nodes. By leveraging multiple GPUs, we show that the training time for a given nowcasting model architecture can be reduced from 59 hours to just over 1 hour. This will allow for faster iterations for improving CNN architectures and will facilitate future advancement in the area of nowcasting.