 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Quasi-Newton Optimization in Large Dimensions Including Deep Network Training
Oct 18, 2024

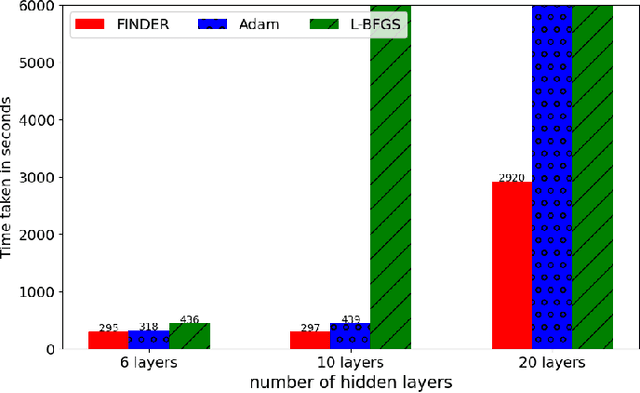

Our proposal is on a new stochastic optimizer for non-convex and possibly non-smooth objective functions typically defined over large dimensional design spaces. Towards this, we have tried to bridge noise-assisted global search and faster local convergence, the latter being the characteristic feature of a Newton-like search. Our specific scheme -- acronymed FINDER (Filtering Informed Newton-like and Derivative-free Evolutionary Recursion), exploits the nonlinear stochastic filtering equations to arrive at a derivative-free update that has resemblance with the Newton search employing the inverse Hessian of the objective function. Following certain simplifications of the update to enable a linear scaling with dimension and a few other enhancements, we apply FINDER to a range of problems, starting with some IEEE benchmark objective functions to a couple of archetypal data-driven problems in deep networks to certain cases of physics-informed deep networks. The performance of the new method vis-\'a-vis the well-known Adam and a few others bears evidence to its promise and potentialities for large dimensional optimization problems of practical interest.
Physics Informed Deep Learning for Strain Gradient Continuum Plasticity
Aug 13, 2024We use a space-time discretization based on physics informed deep learning (PIDL) to approximate solutions of a class of rate-dependent strain gradient plasticity models. The differential equation governing the plastic flow, the so-called microforce balance for this class of yield-free plasticity models, is very stiff, often leading to numerical corruption and a consequent lack of accuracy or convergence by finite element (FE) methods. Indeed, setting up the discretized framework, especially with an elaborate meshing around the propagating plastic bands whose locations are often unknown a-priori, also scales up the computational effort significantly. Taking inspiration from physics informed neural networks, we modify the loss function of a PIDL model in several novel ways to account for the balance laws, either through energetics or via the resulting PDEs once a variational scheme is applied, and the constitutive equations. The initial and the boundary conditions may either be imposed strictly by encoding them within the PIDL architecture, or enforced weakly as a part of the loss function. The flexibility in the implementation of a PIDL technique often makes for its ready interface with powerful optimization schemes, and this in turn provides for many possibilities in posing the problem. We have used freely available open-source libraries that perform fast, parallel computations on GPUs. Using numerical illustrations, we demonstrate how PIDL methods could address the computational challenges posed by strain gradient plasticity models. Also, PIDL methods offer abundant potentialities, vis-\'a-vis a somewhat straitjacketed and poorer approximant of FE methods, in customizing the formulation as per the problem objective.