 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable machine-learning for predicting molecular weight of PLA based on artificial bee colony optimization algorithm and adaptive neurofuzzy inference system
Jan 13, 2025

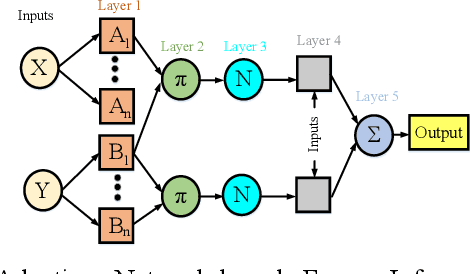

This article discusses the integration of the Artificial Bee Colony (ABC) algorithm with two supervised learning methods, namely Artificial Neural Networks (ANNs) and Adaptive Network-based Fuzzy Inference System (ANFIS), for feature selection from Near-Infrared (NIR) spectra for predicting the molecular weight of medical-grade Polylactic Acid (PLA). During extrusion processing of PLA, in-line NIR spectra were captured along with extrusion process and machine setting data. With a dataset comprising 63 observations and 512 input features, appropriate machine learning tools are essential for interpreting data and selecting features to improve prediction accuracy. Initially, the ABC optimization algorithm is coupled with ANN/ANFIS to forecast PLA molecular weight. The objective functions of the ABC algorithm are to minimize the root mean square error (RMSE) between experimental and predicted PLA molecular weights while also minimizing the number of input features. Results indicate that employing ABC-ANFIS yields the lowest RMSE of 282 Da and identifies four significant parameters (NIR wavenumbers 6158 cm-1, 6310 cm-1, 6349 cm-1, and melt temperature) for prediction. These findings demonstrate the effectiveness of using the ABC algorithm with ANFIS for selecting a minimal set of features to predict PLA molecular weight with high accuracy during processing
DCVSMNet: Double Cost Volume Stereo Matching Network
Feb 26, 2024



We introduce Double Cost Volume Stereo Matching Network(DCVSMNet) which is a novel architecture characterised by by two small upper (group-wise) and lower (norm correlation) cost volumes. Each cost volume is processed separately, and a coupling module is proposed to fuse the geometry information extracted from the upper and lower cost volumes. DCVSMNet is a fast stereo matching network with a 67 ms inference time and strong generalization ability which can produce competitive results compared to state-of-the-art methods. The results on several bench mark datasets show that DCVSMNet achieves better accuracy than methods such as CGI-Stereo and BGNet at the cost of greater inference time.