 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting contextual information to improve stance detection in informal political discourse with LLMs
Feb 04, 2026This study investigates the use of Large Language Models (LLMs) for political stance detection in informal online discourse, where language is often sarcastic, ambiguous, and context-dependent. We explore whether providing contextual information, specifically user profile summaries derived from historical posts, can improve classification accuracy. Using a real-world political forum dataset, we generate structured profiles that summarize users' ideological leaning, recurring topics, and linguistic patterns. We evaluate seven state-of-the-art LLMs across baseline and context-enriched setups through a comprehensive cross-model evaluation. Our findings show that contextual prompts significantly boost accuracy, with improvements ranging from +17.5\% to +38.5\%, achieving up to 74\% accuracy that surpasses previous approaches. We also analyze how profile size and post selection strategies affect performance, showing that strategically chosen political content yields better results than larger, randomly selected contexts. These findings underscore the value of incorporating user-level context to enhance LLM performance in nuanced political classification tasks.
* 14 pages, 7 figures
An Experimental Study on Data Augmentation Techniques for Named Entity Recognition on Low-Resource Domains
Nov 21, 2024Named Entity Recognition (NER) is a machine learning task that traditionally relies on supervised learning and annotated data. Acquiring such data is often a challenge, particularly in specialized fields like medical, legal, and financial sectors. Those are commonly referred to as low-resource domains, which comprise long-tail entities, due to the scarcity of available data. To address this, data augmentation techniques are increasingly being employed to generate additional training instances from the original dataset. In this study, we evaluate the effectiveness of two prominent text augmentation techniques, Mention Replacement and Contextual Word Replacement, on two widely-used NER models, Bi-LSTM+CRF and BERT. We conduct experiments on four datasets from low-resource domains, and we explore the impact of various combinations of training subset sizes and number of augmented examples. We not only confirm that data augmentation is particularly beneficial for smaller datasets, but we also demonstrate that there is no universally optimal number of augmented examples, i.e., NER practitioners must experiment with different quantities in order to fine-tune their projects.
UniformAugment: A Search-free Probabilistic Data Augmentation Approach
Mar 31, 2020
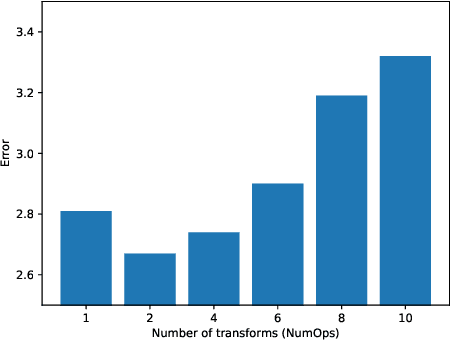
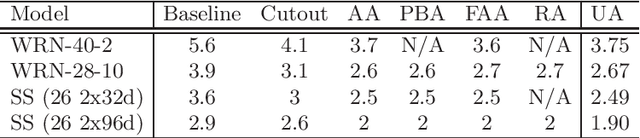

Augmenting training datasets has been shown to improve the learning effectiveness for several computer vision tasks. A good augmentation produces an augmented dataset that adds variability while retaining the statistical properties of the original dataset. Some techniques, such as AutoAugment and Fast AutoAugment, have introduced a search phase to find a set of suitable augmentation policies for a given model and dataset. This comes at the cost of great computational overhead, adding up to several thousand GPU hours. More recently RandAugment was proposed to substantially speedup the search phase by approximating the search space by a couple of hyperparameters, but still incurring non-negligible cost for tuning those. In this paper we show that, under the assumption that the augmentation space is approximately distribution invariant, a uniform sampling over the continuous space of augmentation transformations is sufficient to train highly effective models. Based on that result we propose UniformAugment, an automated data augmentation approach that completely avoids a search phase. In addition to discussing the theoretical underpinning supporting our approach, we also use the standard datasets, as well as established models for image classification, to show that UniformAugment's effectiveness is comparable to the aforementioned methods, while still being highly efficient by virtue of not requiring any search.