 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-based Method for Session-based Recommendations
Jun 22, 2021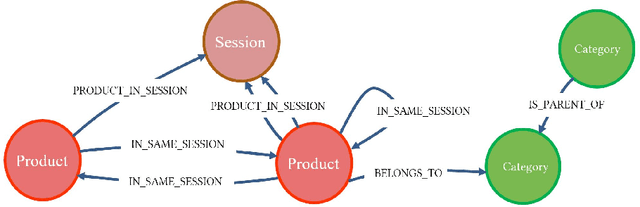

We present a graph-based approach for the data management tasks and the efficient operation of a system for session-based next-item recommendations. The proposed method can collect data continuously and incrementally from an ecommerce web site, thus seemingly prepare the necessary data infrastructure for the recommendation algorithm to operate without any excessive training phase. Our work aims at developing a recommender method that represents a balance between data processing and management efficiency requirements and the effectiveness of the recommendations produced. We use the Neo4j graph database to implement a prototype of such a system. Furthermore, we use an industry dataset corresponding to a typical e-commerce session-based scenario, and we report on experiments using our graph-based approach and other state-of-the-art machine learning and deep learning methods.
Student Performance Prediction Using Dynamic Neural Models
Jun 01, 2021
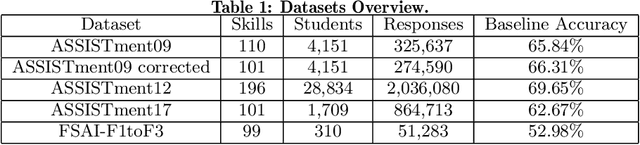

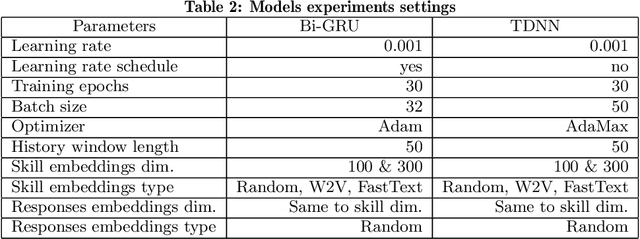
We address the problem of predicting the correctness of the student's response on the next exam question based on their previous interactions in the course of their learning and evaluation process. We model the student performance as a dynamic problem and compare the two major classes of dynamic neural architectures for its solution, namely the finite-memory Time Delay Neural Networks (TDNN) and the potentially infinite-memory Recurrent Neural Networks (RNN). Since the next response is a function of the knowledge state of the student and this, in turn, is a function of their previous responses and the skills associated with the previous questions, we propose a two-part network architecture. The first part employs a dynamic neural network (either TDNN or RNN) to trace the student knowledge state. The second part applies on top of the dynamic part and it is a multi-layer feed-forward network which completes the classification task of predicting the student response based on our estimate of the student knowledge state. Both input skills and previous responses are encoded using different embeddings. Regarding the skill embeddings we tried two different initialization schemes using (a) random vectors and (b) pretrained vectors matching the textual descriptions of the skills. Our experiments show that the performance of the RNN approach is better compared to the TDNN approach in all datasets that we have used. Also, we show that our RNN architecture outperforms the state-of-the-art models in four out of five datasets. It is worth noting that the TDNN approach also outperforms the state of the art models in four out of five datasets, although it is slightly worse than our proposed RNN approach. Finally, contrary to our expectations, we find that the initialization of skill embeddings using pretrained vectors offers practically no advantage over random initialization.