 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the Role of Large Language Models in the Evolution of Astronomy Research?
Sep 30, 2024
ChatGPT and other state-of-the-art large language models (LLMs) are rapidly transforming multiple fields, offering powerful tools for a wide range of applications. These models, commonly trained on vast datasets, exhibit human-like text generation capabilities, making them useful for research tasks such as ideation, literature review, coding, drafting, and outreach. We conducted a study involving 13 astronomers at different career stages and research fields to explore LLM applications across diverse tasks over several months and to evaluate their performance in research-related activities. This work was accompanied by an anonymous survey assessing participants' experiences and attitudes towards LLMs. We provide a detailed analysis of the tasks attempted and the survey answers, along with specific output examples. Our findings highlight both the potential and limitations of LLMs in supporting research while also addressing general and research-specific ethical considerations. We conclude with a series of recommendations, emphasizing the need for researchers to complement LLMs with critical thinking and domain expertise, ensuring these tools serve as aids rather than substitutes for rigorous scientific inquiry.
Toward an understanding of the properties of neural network approaches for supernovae light curve approximation
Sep 15, 2022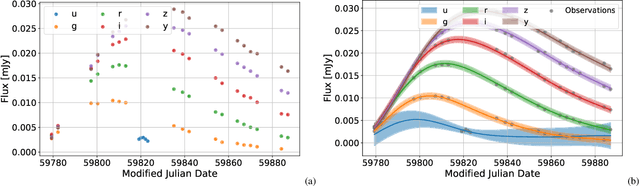
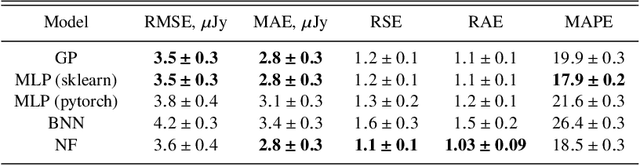
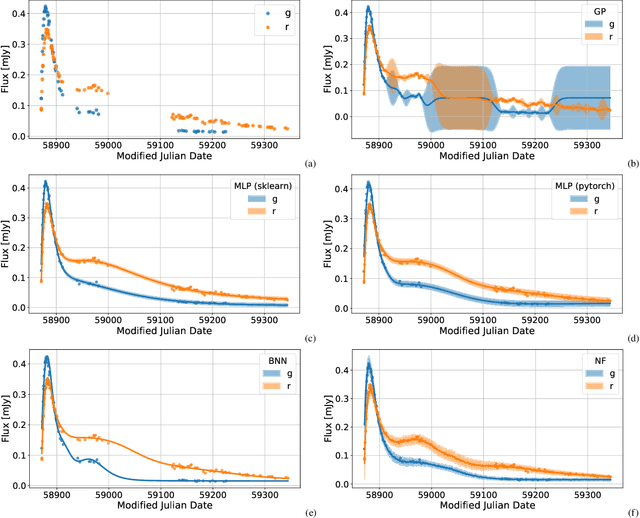

The modern time-domain photometric surveys collect a lot of observations of various astronomical objects, and the coming era of large-scale surveys will provide even more information. Most of the objects have never received a spectroscopic follow-up, which is especially crucial for transients e.g. supernovae. In such cases, observed light curves could present an affordable alternative. Time series are actively used for photometric classification and characterization, such as peak and luminosity decline estimation. However, the collected time series are multidimensional, irregularly sampled, contain outliers, and do not have well-defined systematic uncertainties. Machine learning methods help extract useful information from available data in the most efficient way. We consider several light curve approximation methods based on neural networks: Multilayer Perceptrons, Bayesian Neural Networks, and Normalizing Flows, to approximate observations of a single light curve. Tests using both the simulated PLAsTiCC and real Zwicky Transient Facility data samples demonstrate that even few observations are enough to fit networks and achieve better approximation quality than other state-of-the-art methods. We show that the methods described in this work have better computational complexity and work faster than Gaussian Processes. We analyze the performance of the approximation techniques aiming to fill the gaps in the observations of the light curves, and show that the use of appropriate technique increases the accuracy of peak finding and supernova classification. In addition, the study results are organized in a Fulu Python library available on GitHub, which can be easily used by the community.
Supernova Light Curves Approximation based on Neural Network Models
Jun 27, 2022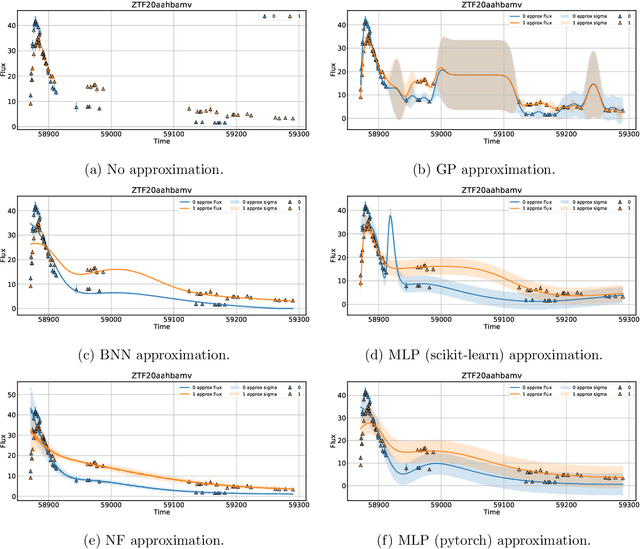
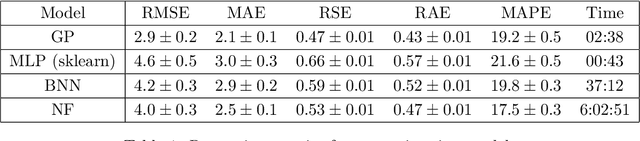

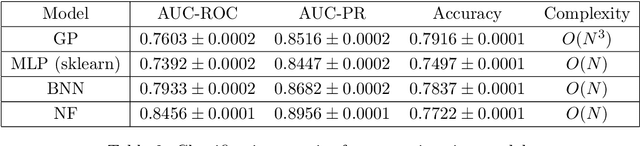
Photometric data-driven classification of supernovae becomes a challenge due to the appearance of real-time processing of big data in astronomy. Recent studies have demonstrated the superior quality of solutions based on various machine learning models. These models learn to classify supernova types using their light curves as inputs. Preprocessing these curves is a crucial step that significantly affects the final quality. In this talk, we study the application of multilayer perceptron (MLP), bayesian neural network (BNN), and normalizing flows (NF) to approximate observations for a single light curve. We use these approximations as inputs for supernovae classification models and demonstrate that the proposed methods outperform the state-of-the-art based on Gaussian processes applying to the Zwicky Transient Facility Bright Transient Survey light curves. MLP demonstrates similar quality as Gaussian processes and speed increase. Normalizing Flows exceeds Gaussian processes in terms of approximation quality as well.